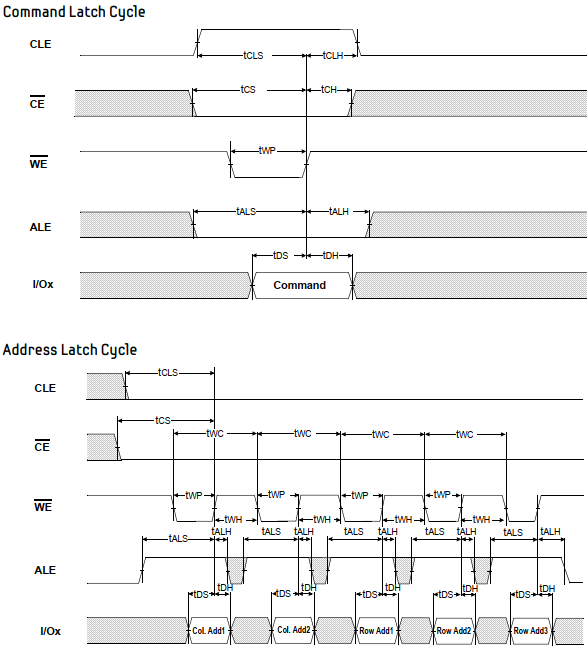
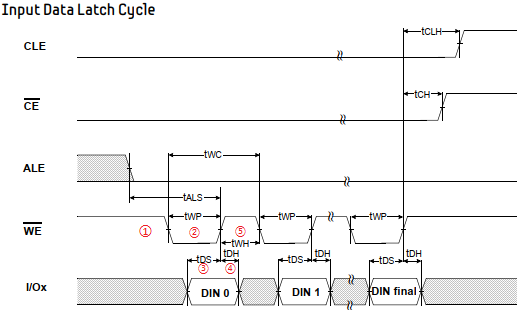
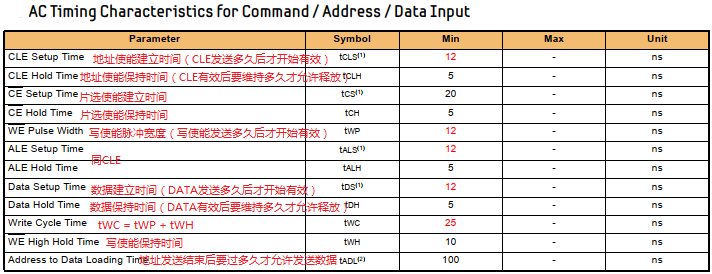
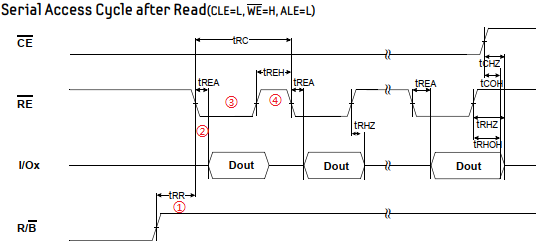
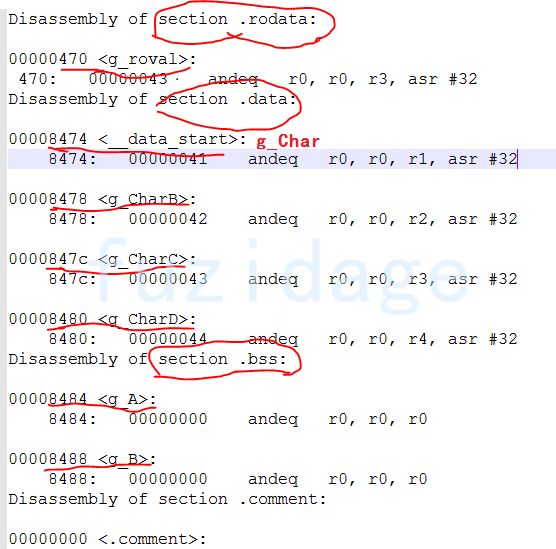
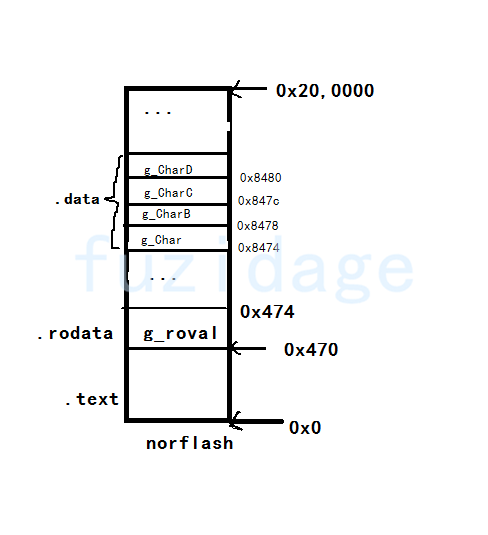
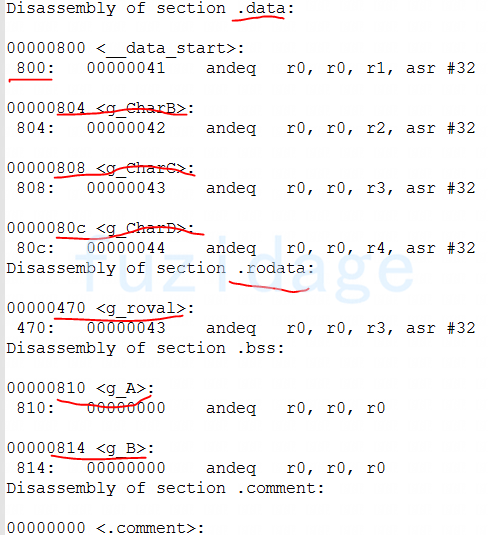
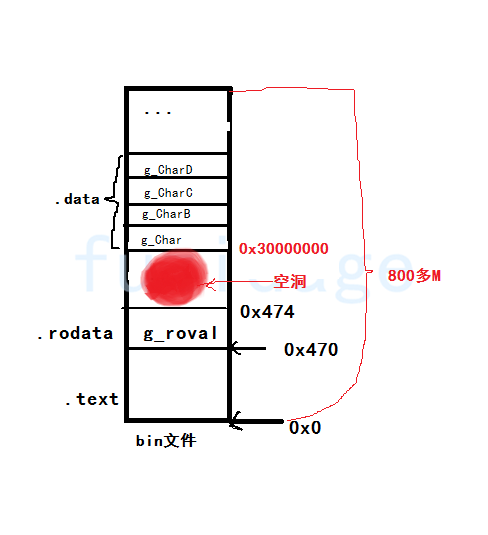
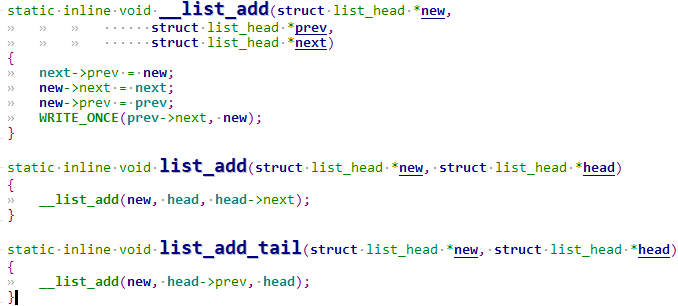
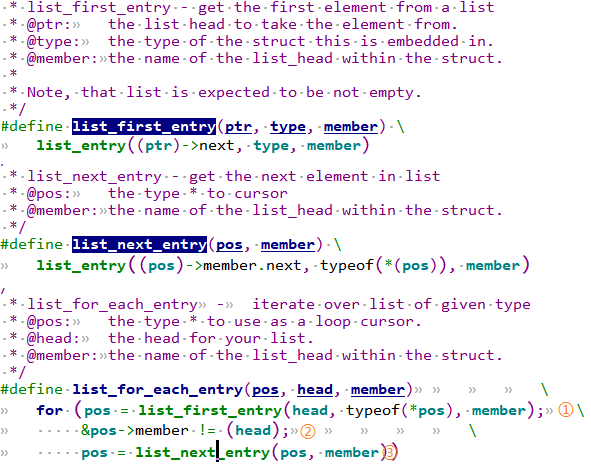
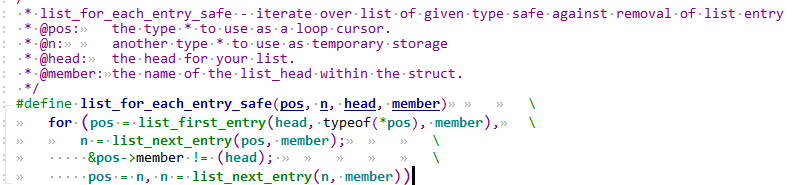
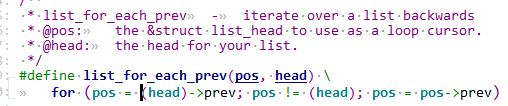
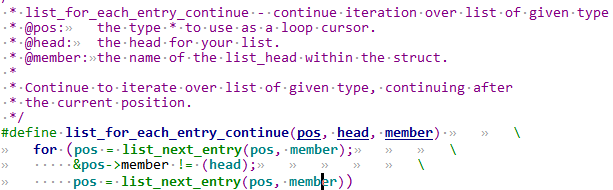
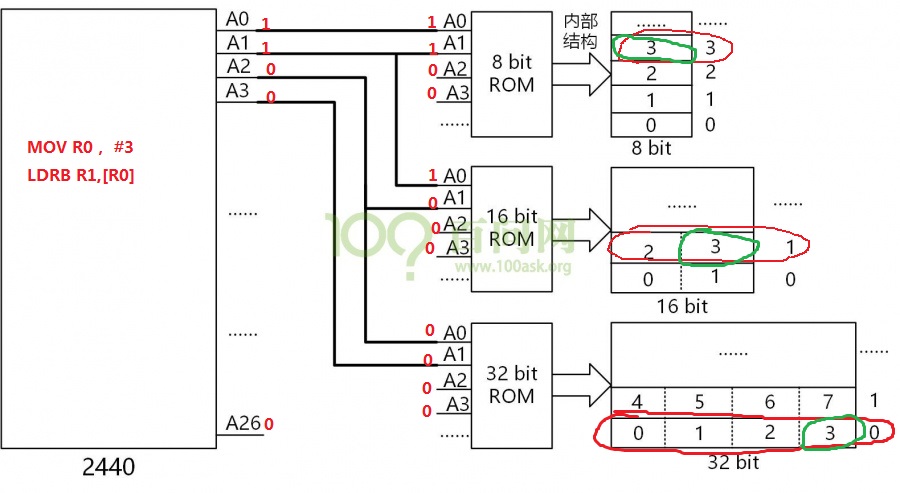
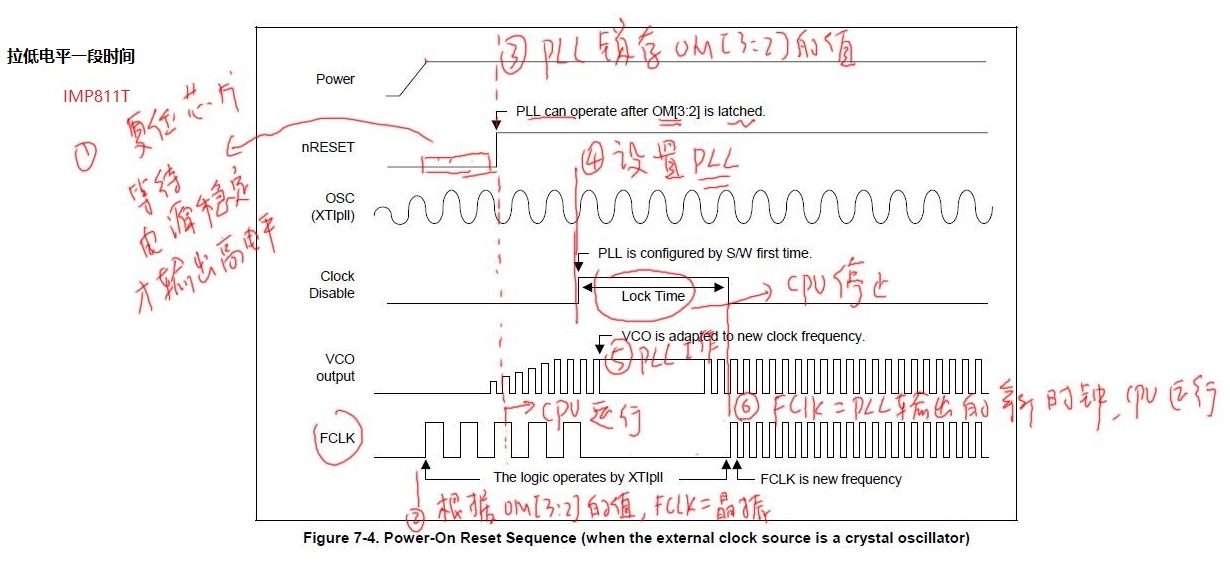
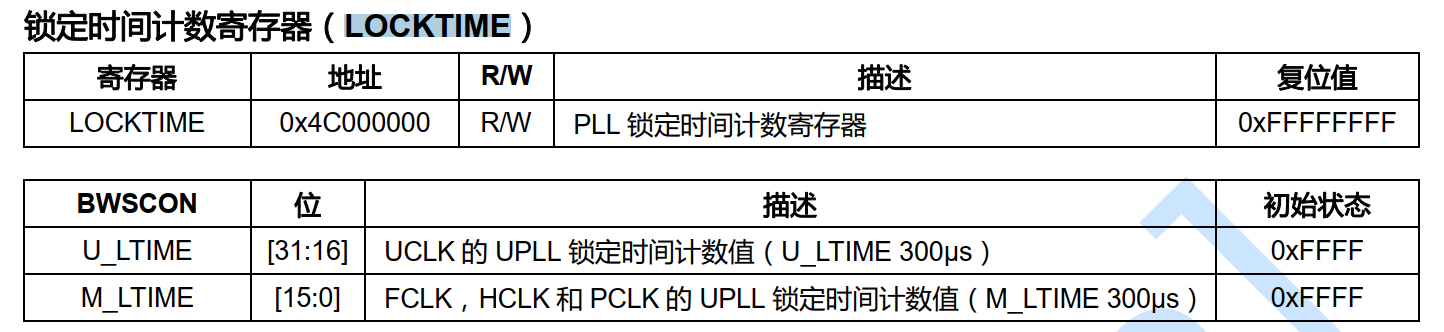
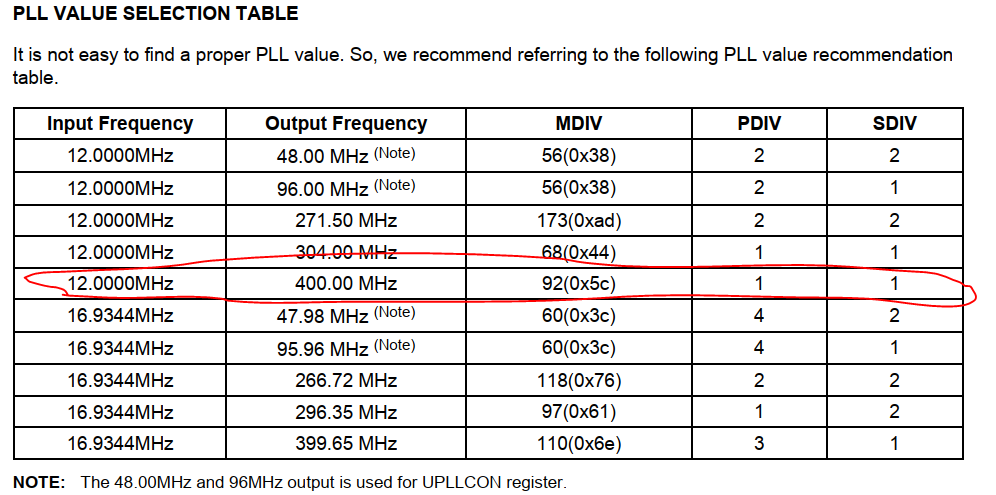
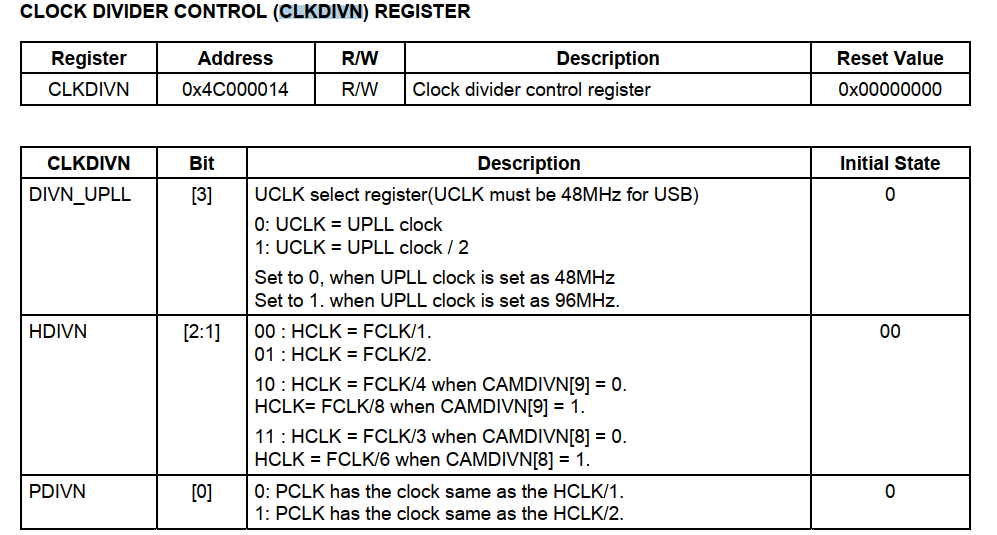
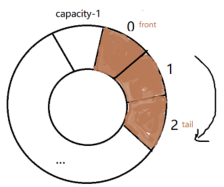
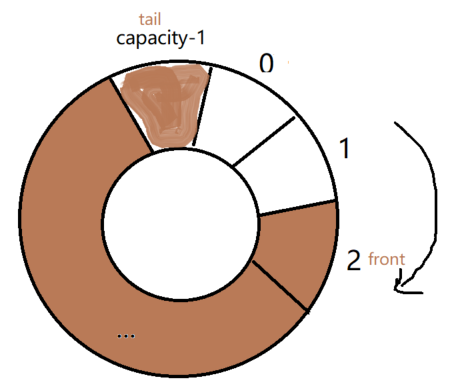
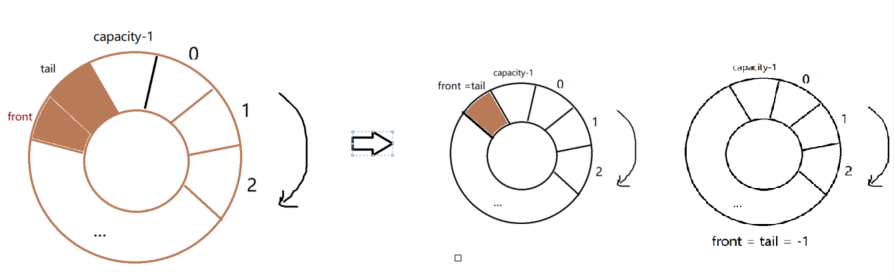
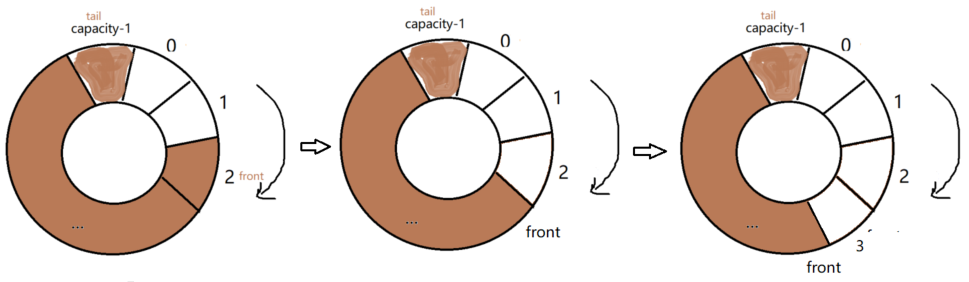
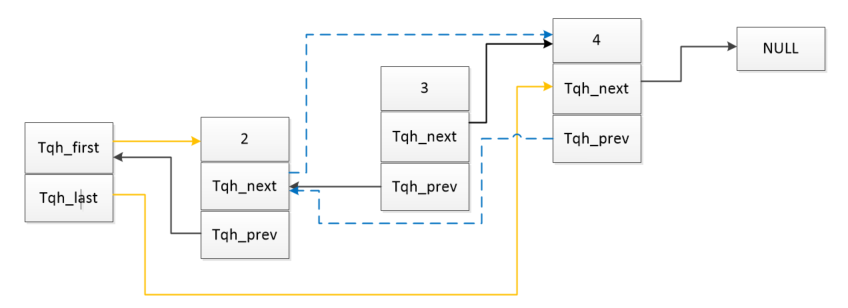
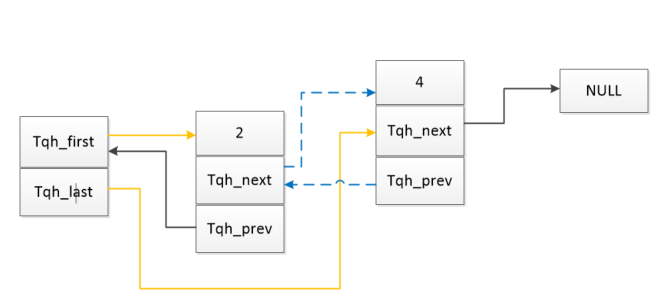
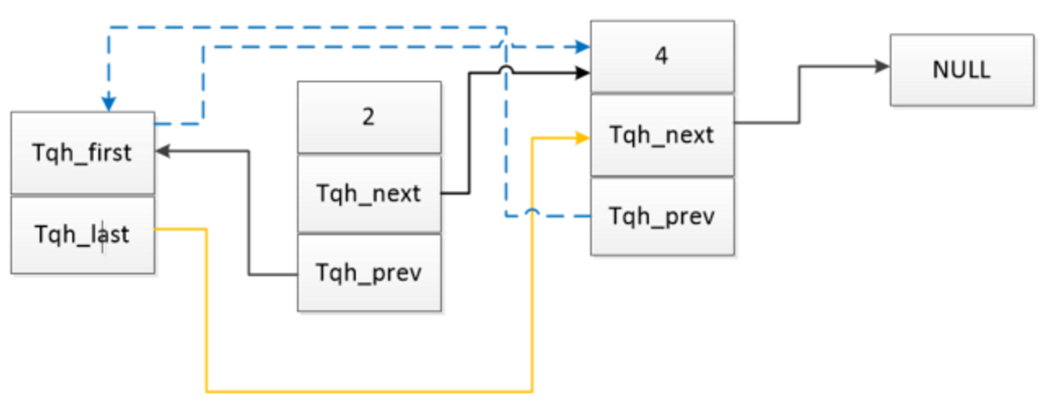
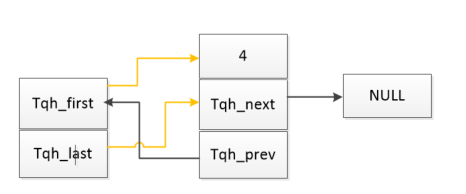
1 异常中断引入 在arm架构的处理器中,cpu有7中工作模式,2中工作状态。
1.1 CPU模式 7种Mode: 除了usr/sys,其他5种都是异常模式。我们知道中断属于异常的2中,中断有irq,fiq。
usr
sys
undefined(und)
Supervisor(svc)
Abort(abt)
irq
fiq
用户模式
系统模式
未定义指令异常模
svc管理模式
终止模式(1.指令预取终止(读写某条错误的指令导致终止运行);2.数据访问终止(读写某个非法地址程序终止))
irq中断
快中断
除了usr模式,其他6中为特权模式。 CPU无法从usr模式直接进入特权模式。不能直接进入特权模式,那么怎么进入特权模式 呢?
可以通过设置CPSR 进入其他模式。
1.2 工作State ARM state
Thumb state(几乎用不上)
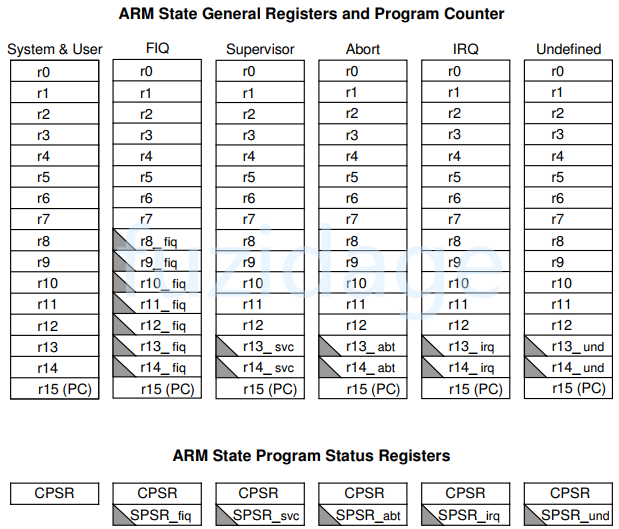
1.3 ARM寄存器 (1)通用寄存器:
(2)备份寄存器(banked register):
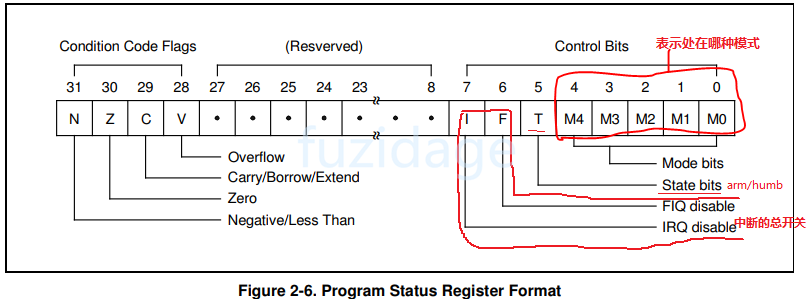
CPSR:当前程序状态寄存器(Current Program Status Register) 反映程序处在那种状态
SPSR:CPSR的备份寄存器 (Saved Program Status Register) 用来保存"被中断前的CPSR"
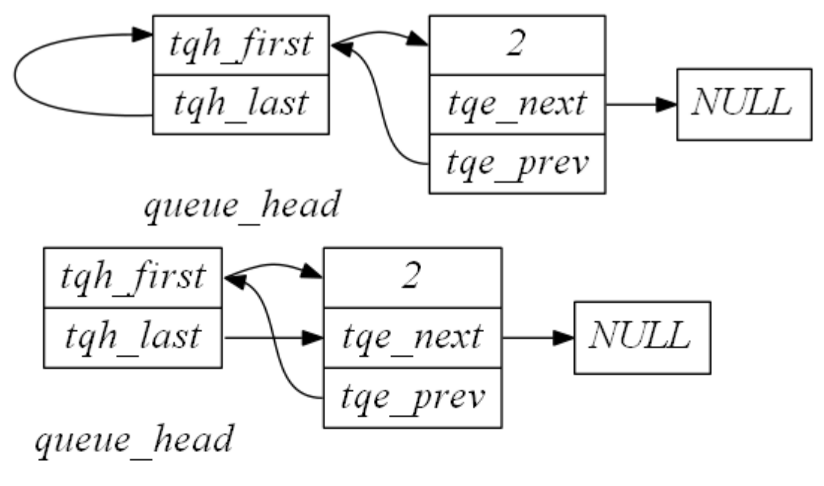
下图是我们arm状态下的通用寄存器和程序状态寄存器
R13是SP(栈指针) R14是LR (link register),程序跳转或者发成异常时的返回地址R15是PC (程序计数器)
假设cpu执行:
1 2 mov R0, R8 mov R0,R8_fiq
在usr/System 模式下访问的R8, 但是在FIQ模式下,访问R8是访问FIQ模式专属的R8寄存器,不是同一个物理上的寄存器。
为什么快中断(FIQ)有那么多专属寄存器?中断处理流程 :
1 保存现场(保存被中断模式的寄存器)---(比如程序正在sys/usr模式下运行,当发生中断时,需要把R0-R14这些寄存器全部保存下来)
2 异常处理(去分辨是哪一个中断源产生了中断,去执行对应的中断服务程序)
3 恢复现场(恢复被中断时保存下来的寄存器R0-R14)
但如果是快中断,那么我就不需要保存系统/用户模式下的R8 ~ R12这几个寄存器,因为在FIQ模式下有自己专属的R8 ~ R12寄存器,省略保存寄存器的时间,加快处理速度,所以它才称得上快中断。
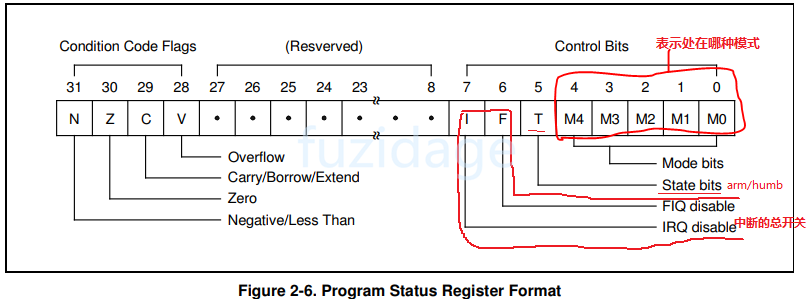
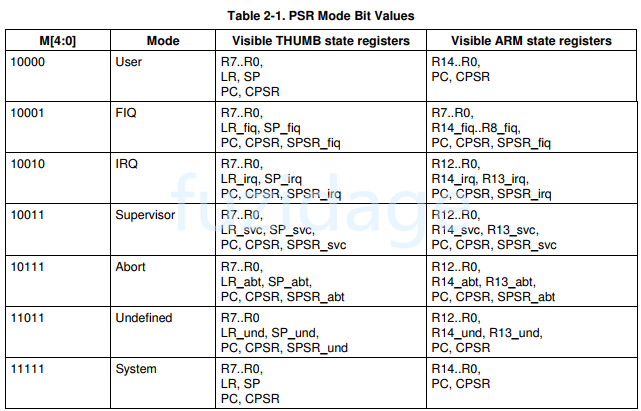
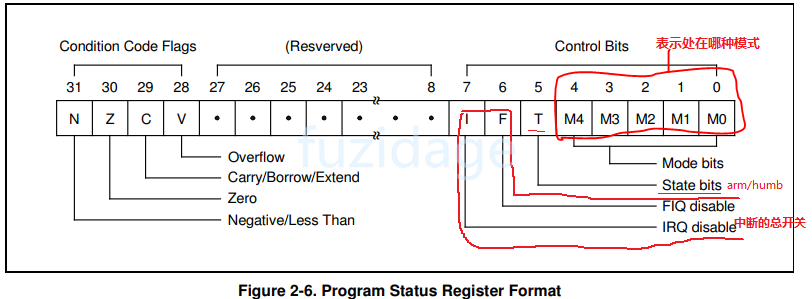
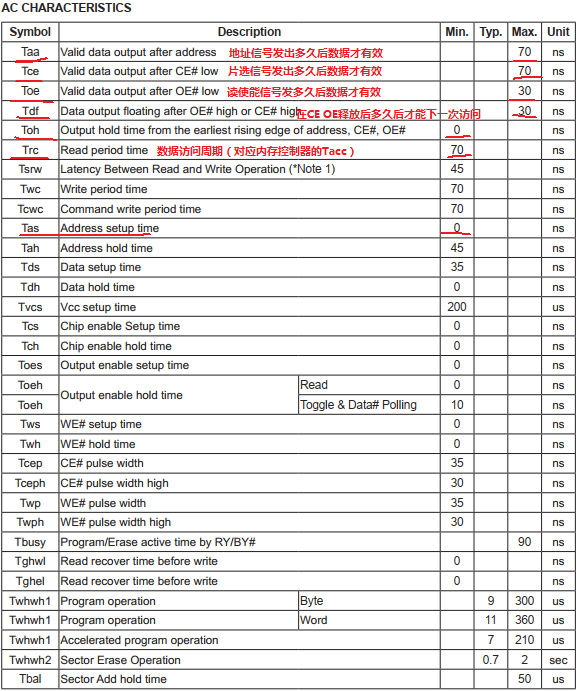
1.3.1 CPSR程序状态寄存器 在异常中断中PSR寄存器会使用的很频繁,PSR寄存器的格式如下图:
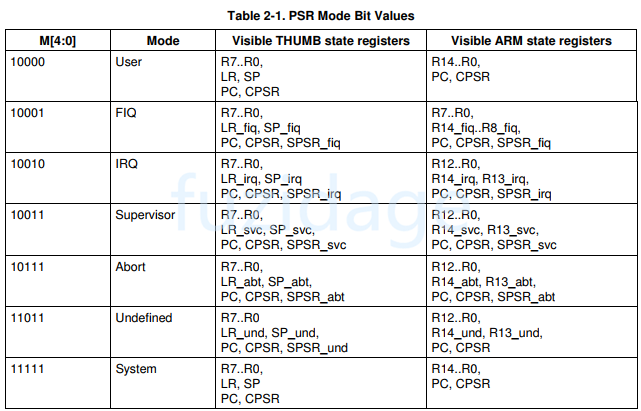
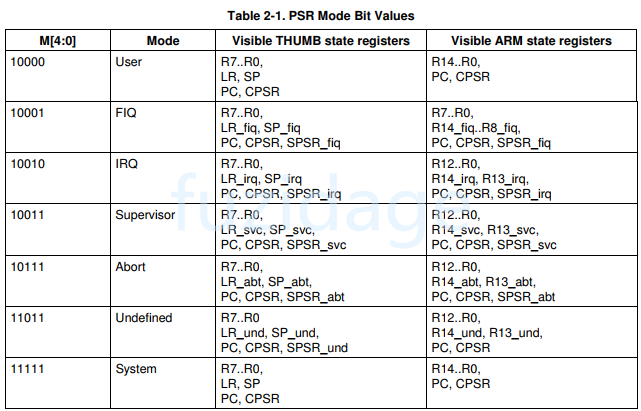
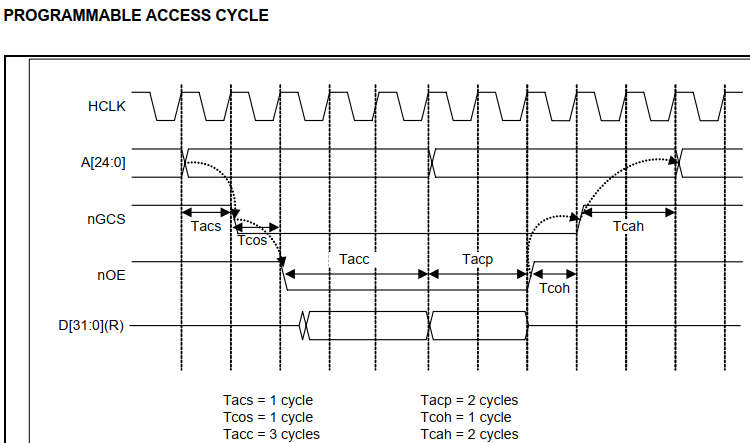
我们再来看看下表,反映的是PSR的 M[4:0]与arm工作模式的关系:
我们可以按照上图的对应关系设置CPSR,让其进入与之对应的模式。
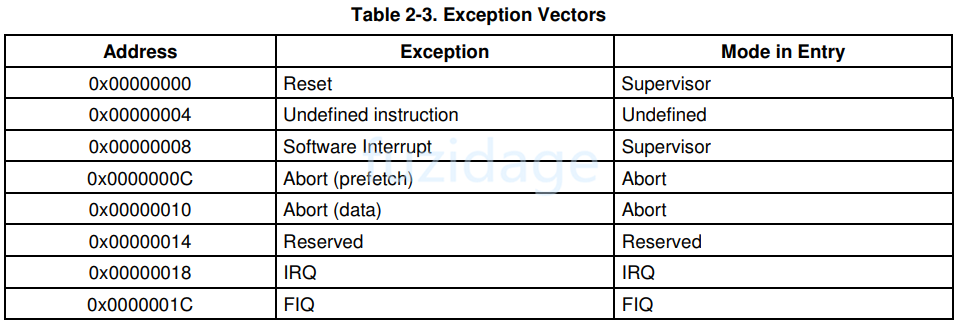
1.3.2 SPSR程序状态备份寄存器 1.4 异常向量表 异常向量 :不同的异常有不同的入口函数,那么这个异常入口函数的地址就是存放在该异常向量的位置。从该异常向量读取到的数据就是异常入口函数的地址。异常向量表 :就是由异常向量组成的集合。
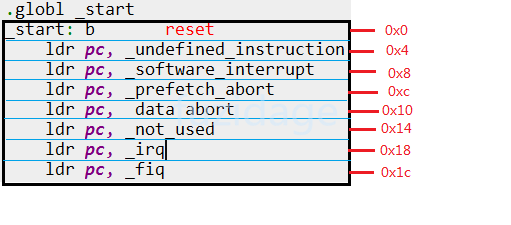
下图是从uboot源代码中截取的smdk2410 的异常向量表:
1 2 3 4 5 6 7 8 9 .globl _start _start: b reset ldr pc, _undefined_instruction ldr pc, _software_interrupt ldr pc, _prefetch_abort ldr pc, _data_abort ldr pc, _not_used ldr pc, _irq ldr pc, _fiq
异常向量表对应的地址如下图:
2 异常处理流程 CPU是如何进入到中断模式,执行中断服务程序的?
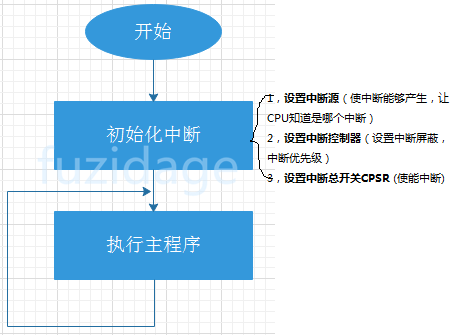
2.1 中断前 下图是中断未触发前的程序执行过程:
2.1.1 初始化中断 1,设置中断源(使中断能够产生,让CPU知道是哪个中断)
2,设置中断控制器(设置中断屏蔽,中断优先级)
3,设置中断总开关CPSR (使能中断)
2.2 中断产生后 举个栗子:按键按下,产生按键irq。
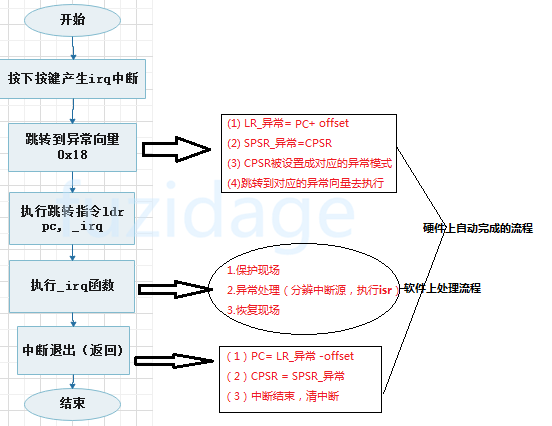
2.2.1 硬件上的处理流程 cpu强制跳转到异常向量表上对应的_irq异常向量(0x18)去读取指令(这个是CPU强制执行的,不需要我们去控制)。
具体的进入中断向量和中断返回流程见下图:
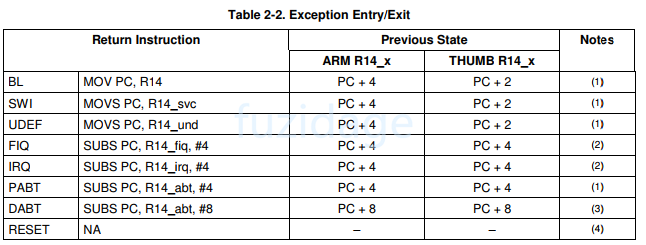
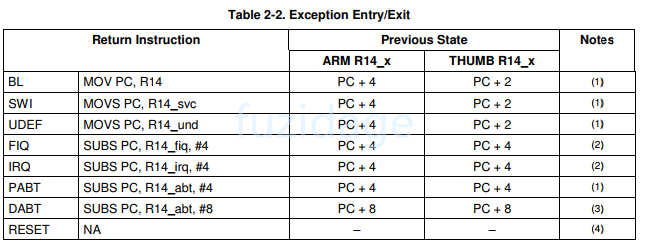
1 2 3 4 5 6 7 8 9 进入: (1 ) LR_异常=PC + offset(具体多少看下图) (2 )SPSR_异常=被中断前的程序模式CPSR (3 ) CPSR被设置成对应的异常模式 (4 )跳转到对应的异常向量去执行 退出(返回):进入和退出就是一个逆过程 (1 )PC= LR_异常 -offset (2 )被中断前的程序模式CPSR = SPSR_异常 (3 )中断结束,清中断
进入异常和返回异常时pc和lr的关系如下图:
从图中我们发现进入不同异常,offset的值也是有差异的。
2.2.2 软件上的处理流程 1.当跳转到irq异常向量(0x18)后,发现该处是一条跳转指令“ldr pc, _irq”,
那么会通过ldr绝对跳转指令跳到到真正的中断处理函数_irq去执行。
2.那么在_irq的函数中我们需要按照之前说的**中断处理流程**去执行:
(1)保存现场
(2)异常处理(去分辨是哪一个中断源产生了中断,去执行对应的中断服务程序)
(3)恢复现场
流程图总结下中断产生后的详细处理过程:
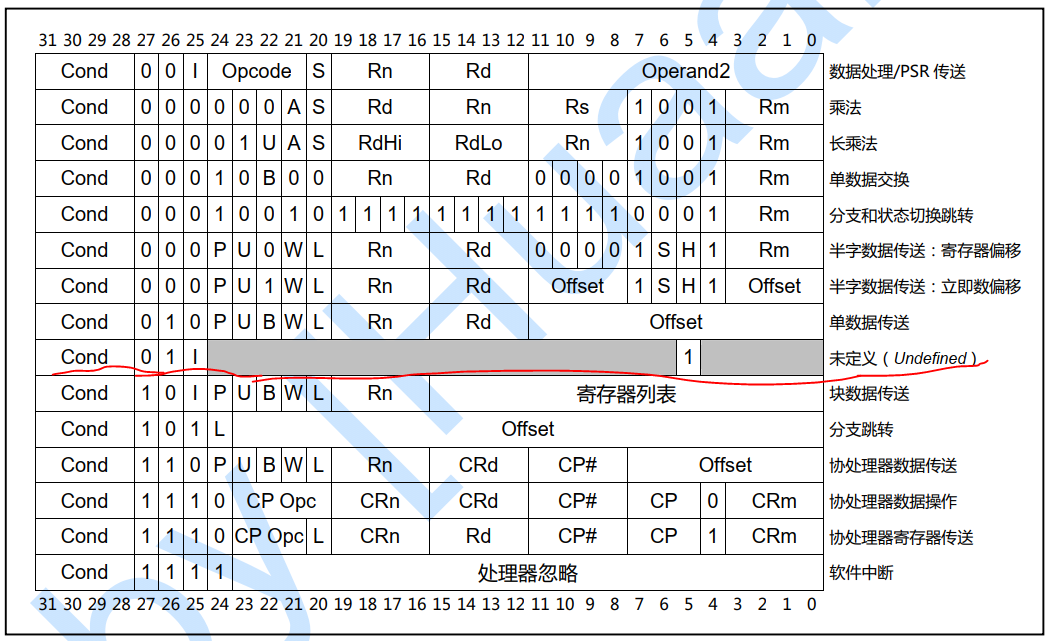
3 中断实例 3.1 und-未定义指令异常 先来看下当cpu解析到什么样的指令才会触发未定义指令异常呢?
从上面的arm指令格式中可知,只要指令码属于划线的格式,就属于未定义指令异常。
3.1.1 汇编向c函数传参 我们知道汇编给C语言函数传参是通过r0,r1,…通过堆栈的方式去传递的参数,比如r0=1, r1=2;那么在被调用的c函数中argv0就是r0, argv1就是r1…,那么我们如果通过汇编给C函数传递字符串呢?
声明und_string为一个字符串:
1 2 und_string: .string "undefined instruction exception"
然后用ldr r1, =und_string,这样r1中就保存了und_string的地址。
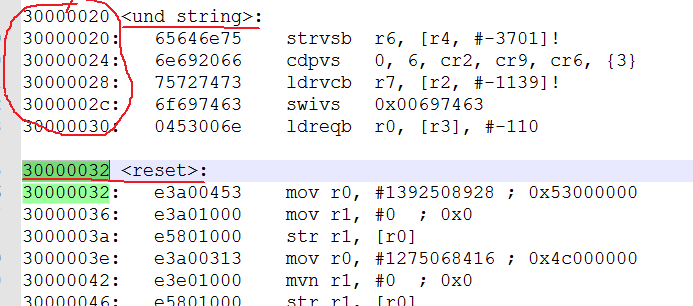
3.1.2 und异常程序示例 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 .text .global _start _start: b reset b do_und reset: ... bl print1 und_code: .word 0xdeadc0de ; bl print2 ...
在未定义指令异常前后加上打印print1, print2,如果出现未定义指令异常后,就会跳到0x4的地方去读取指令,print2也就没法执行 。
当跳转到0x4的中断向量后,发现此处是一条跳转指令bl do_und, 我们再到未定义指令异常的服务程序do_und中打印出und_string这个字符串的内容。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 do_und: ldr sp, =0x34000000 stmdb sp!, {r0-r12, lr} mrs r0, cpsr ldr r1, =und_string bl printException ldmia sp!, {r0-r12, pc}^
下面来分析一下这个未定义指令异常服务程序:
进入未定义指令异常服务do_und之前硬件自动完成的事情如下:
lr_und保存有被中断模式中的下一条即将执行的指令的地址
SPSR_und保存有被中断模式的CPSR
CPSR中的M4-M0被设置为11011, 进入到und模式
跳到0x4的地方执行程序 (bl do_und)
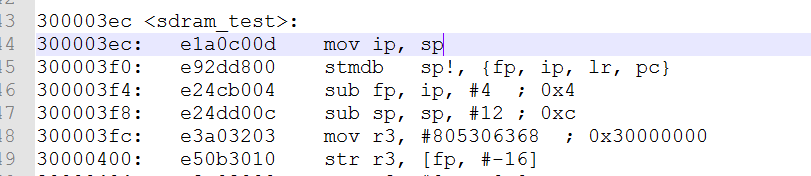
进入指令异常服务程序do_und后,我们需要保存现场,处理und异常,恢复现场,注意:由于发生了cpu模式切换,如果要用到栈,那么先要设置对应模式的栈。 由于栈的地址是向下生长的,这里我就用sdram的末位地址作为栈指针,把sp_und=0x34000000。
在und异常服务程序中有可能会用到栈, 所以先保存现场,通过stmdb sp!, {r0-r12, lr}语句把栈中的值备份到r0-r12和lr,然后恢复现场的时候通过ldmia sp!, {r0-r12, pc}^,详见上面的注释。
我们看到保存现场后,我们把cpsr的值放到r0, 把und_string放到r1, 然后用bl printException调用c函数,这样我们的c函数printException就能收到汇编传过来的参数,一个是cpsr模式(r0),一个是und_string汇编传过来的字符串(r1)。我们用C函数实现printException:
1 2 3 4 5 6 7 void printException (unsigned int cpsr, char *str) { puts ("Exception! cpsr = " ); printHex(cpsr); puts (" " ); puts (str); puts ("\n\r" ); }
完整的代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 .text .global _start _start: b reset b do_und do_und: ldr sp, =0x34000000 stmdb sp!, {r0-r12, lr} mrs r0, cpsr ldr r1, =und_string bl printException ldmia sp!, {r0-r12, pc}^ und_string: .string "undefined instruction exception" reset: bl copy2sdram bl clean_bss bl uart0_init bl print1 und_code: .word 0xdeadc0de bl print2 ldr pc, =main halt: b halt
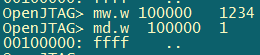
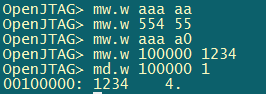
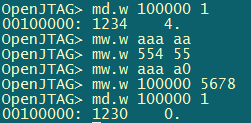
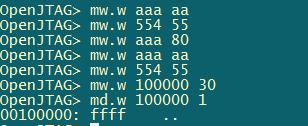
测试结果 如下:
打印出print1中的字符串‘abc’后,紧接着打印printException函数中的结果,cpsr=0x600000db,那么对应的M[4:0]=11011, 对应下图为und模式。然后从und异常返回,恢复原来的模式继续执行。
3.1.3 示例改进 3.1.3.1 指令4字节对齐 我们将上面的代码的und_string字符串修改一下:
1 2 3 4 5 6 7 8 ... und_string: .string "undef instruction" reset: ...
编译烧录再次运行,发现没有任何打印输出,这是为什么呢?我明明只是把und_string字符串改了一下呀。
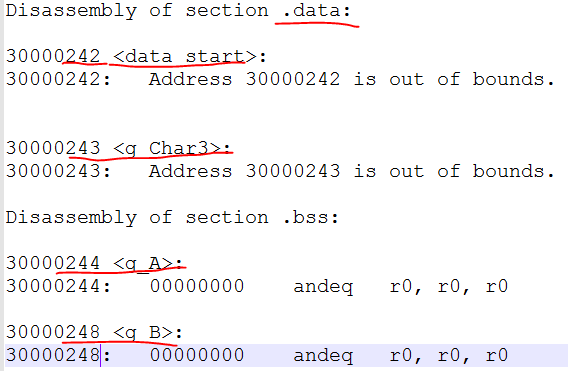
查看反汇编:
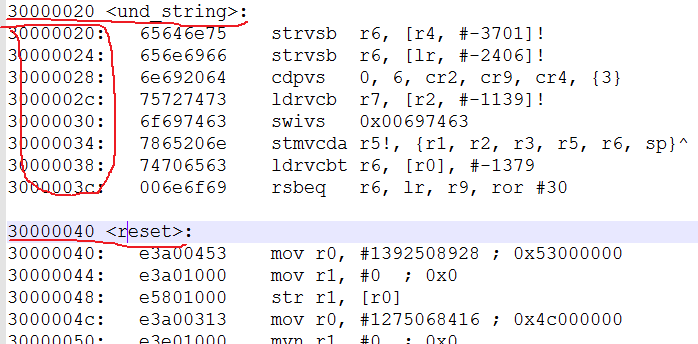
我们发现reset的地址是0x30000032,竟然不是4字节对齐的,我们知道arm指令集是以4字节为基本单位的,那么这里没有对齐,肯定无法解析指令。那么我们手工改进代码如下:
1 2 3 ... und_string: .string "undef instruction"
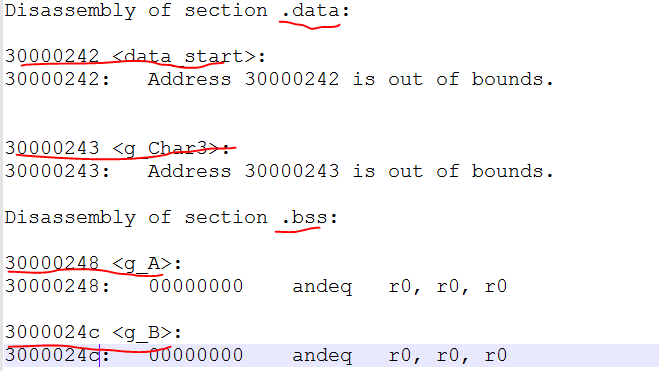
.align 4
我们再来看看反汇编,发现reset的地址是30000040,是以4字节对齐的,再次烧录运行,发现能够正常输出print1, 能够进入未定义指令异常。
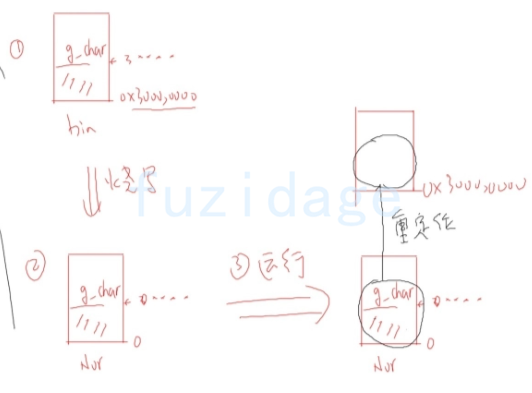
3.1.3.2 绝对跳转进入异常向量 如果我们程序非常大,中断向量入口代码的地址可能会大于sram的容量4k,比如do_und和do_swi,那么这个时候就需要用绝对跳转。
1 2 3 4 5 .text .global _start _start: b reset b do_und
将上面的相对跳转换成如下代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 .text .global _start _start: b reset ldr pc, und_addr ldr pc, swi_addr ... ... und_addr: .word do_und swi_addr: .word do_swi
这样我们的do_und, do_swi就可放在4k之外的地方, 放到sdram。
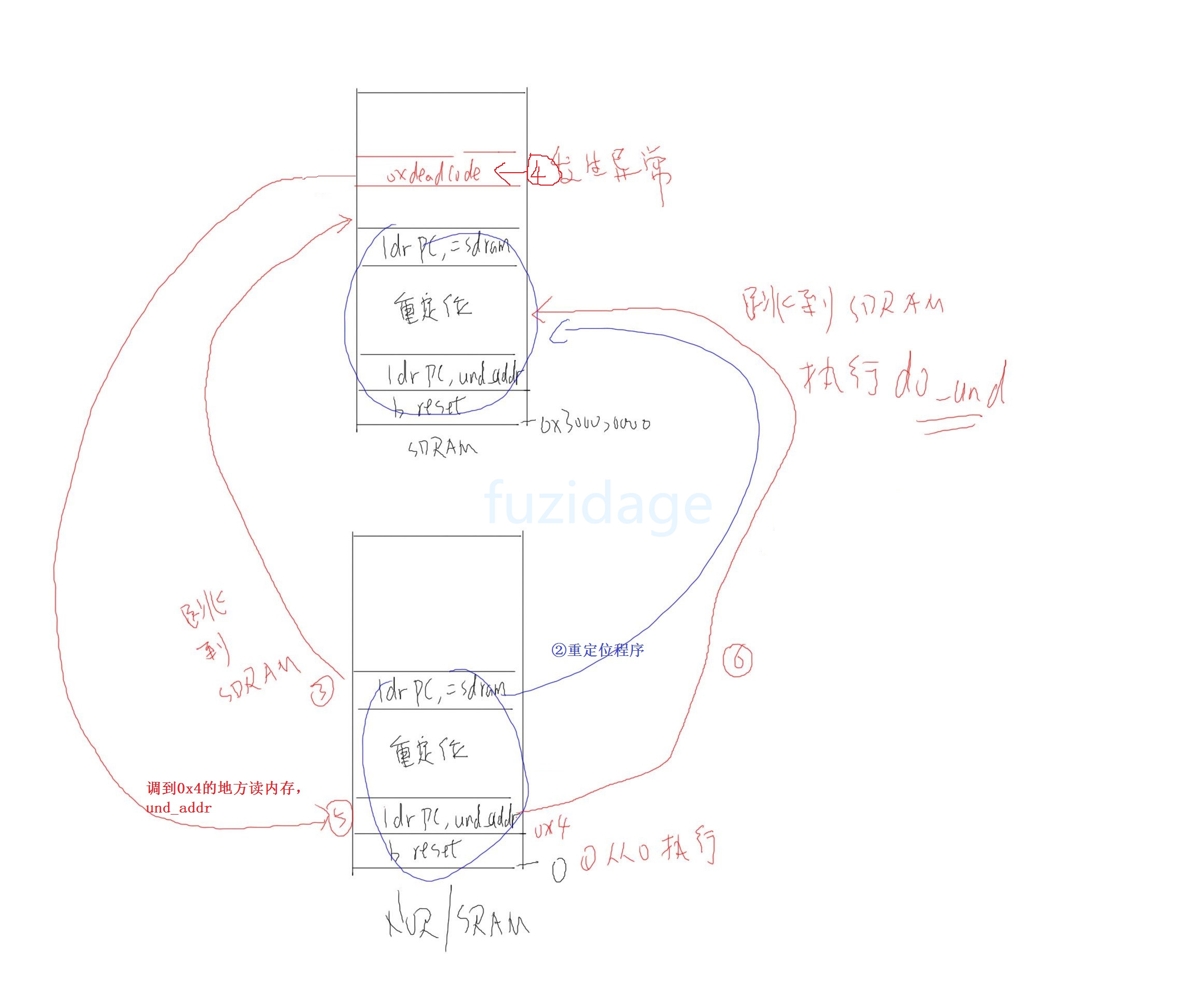
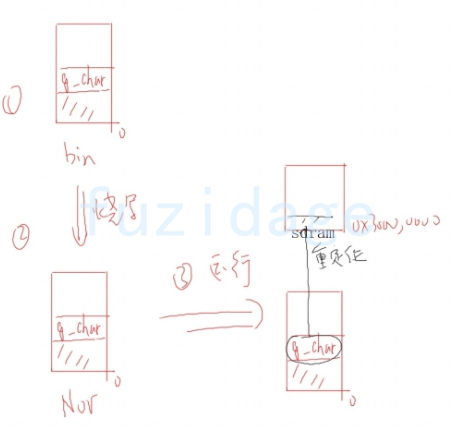
3.1.3.3 重定位后跳转sdram上执行 我们现在不断增加的程序代码量,那么有可能在 ldr pc, =main 这条指令执行之前程序就已经超过4k。那么我们当从nand启动的时候,还没执行到ldr pc, =main这句来,就无法取指令执行了。nor同理超过2M也就无法取指令执行了。 所以我们干脆重定位完代码后就直接跳转到sdram上去执行,代码简要概述如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 ... reset: ldr pc, =sdram sdram: ... ldr pc, =main halt: b halt
我们再来分析下整个程序执行过程:
1.一上电,cpu从0地址执行,执行b reset(进行初始化硬件)
2.重定位程序
3.跳转到sdram去继续执行
4.执行到 deadc0de,发生未定义指令异常
5.跳转到异常向量表的0x4地址去执行
6.跳转到sdram上执行异常处理函数(do_und)
7.异常返回,继续执行
3.2 swi-软中断 arm有7中工作模式,除了usr模式,其他6种都是特权模式。
我们知道usr模式无法修改CPSR直接进入其他特权模式,但linux应用程序一般运行在usr模式,既然usr模式权限非常低,是无法直接访问硬件寄存器的,那么它是如何访问硬件的呢?
1 linux应用程序是通过系统调用,从而进入内核态,运行驱动程序来访问的硬件,那么系统调用又是如何实现的呢,就是通过软中断swi指令来进入svc模式,进入到svc模式后当然就能访问硬件啦。
所以我们的应用程序在usr模式想访问硬件,必须切换模式:
有以下两种方式:
1 2 1. 发生异常或中断(被动的)2. swi + 某个值(主动的)
3.2.1 进入软中断swi s3c2440 一上电会跳到0地址(reset复位)执行代码,此时CPU处于svc模式,2440异常向量表如下图所示:
为了验证usr模式能够主动的通过swi软中断指令来进入svc模式, 我们先将模式切换到usr模式,那么这个时候就不能访问硬件了,也不能直接修改cpsr直接进入其他模式。
从上图我们设置CPSR让M4-M0处在10000,这样就进入了usr模式。修改start.s如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 .global _start _start: b reset ldr pc, und_addr ldr pc, swi_addr ... und_addr: .word do_und swi_addr: .word do_swi reset: mrs r0, cpsr bic r0, r0, #0xf msr cpsr, r0 ldr sp, =0x33f00000 swi 0x123 ldr pc, =main halt: b halt
那么当执行到swi 0x123,就会触发SWI异常, 进入0x8的向量去执行,调用do_swi,我们参考do_und实现我们的软中断服务程序do_swi。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 do_swi: ldr sp, =0x33e00000 stmdb sp!, {r0-r12, lr} mrs r0, cpsr ldr r1, =swi_string bl printException ldmia sp!, {r0-r12, pc}^ swi_string: .string "swi exception"
完整代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 .global _start b reset ldr pc, und_addr ldr pc, swi_addr ... und_addr: .word do_und swi_addr: .word do_swi do_swi: ldr sp, =0x33e00000 stmdb sp!, {r0-r12, lr} mrs r0, cpsr ldr r1, =swi_string bl printException ldmia sp!, {r0-r12, pc}^ swi_string: .string "swi exception" .align 4 reset: mrs r0, cpsr bic r0, r0, #0xf msr cpsr, r0 ldr sp, =0x33f00000 swi 0x123 ldr pc, =main halt: b halt
do_swi中调用printException,打印出了软中断异常的字符串和CPSR对应的svc模式。
3.2.1.1 打印出swi软中断号 我们要读出swi 0x123指令,我们知道当执行完swi 0x123指令以后,会发生swi异常,那么lr_svc = PC + offset。从下图看出offset是4:
修改中断服务函数如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 do_swi: ldr sp, =0x33e00000 stmdb sp!, {r0-r12, lr}
我们要把lr拿出来保存,因为bl printException会破坏lr,那么把lr保存在哪个个寄存器比较好呢?
我们知道当调用bl printException可能会修改某些寄存器,但是又会恢复这些寄存器,那么得知道它会保护哪些些寄存器。
在子程序中,使用R4~R11来保存局部变量,子程序进入时必须保存这些寄存器的值,在返回前必须恢复这些寄存器的值。所以对于 r4 ~ r11在C函数里会保存这几个寄存器,执行完C函数再把它释放掉并且恢复原来的值。我们把lr 保存在r4寄存器里,r4寄存器不会被C语言破坏。
1 2 3 4 5 mov r4, lr mrs r0, cpsr ldr r1, =swi_string bl printException
当执行完swi 0x123指令后,会发生swi异常,swi异常模式里的lr寄存器会保存下一条指令的地址(即’ldr pc, =main’),我们把lr寄存器的地址减去4就是swi 0x123这条指令的地址。
把r4的寄存器赋给r0让后打印我们得写出打印函数:
1 2 3 4 5 6 7 8 9 10 mov r0, r4 sub r0, r4, #4 bl printSWIVal ldmia sp!, {r0-r12, pc}^ swi_string: .string "swi exception"
在uart.c添加printSWIVal打印函数:
1 2 3 4 5 void printSWIVal (unsigned int *pSWI) { puts ("SWI val = " ); printHEx(*pSWI & ~0xff000000 ); puts ("\n\r" ); }
3.3 irq-外部中断 3.3.1 引入外部中断 我们想实现一个按键点灯程序,我们知道有以下两种方案:
1 2 1. 轮询方案:轮询检测按键的电平状态,当检测到被按下后,对应的gpio会拉低,点亮对应的led;(略)2. 中断方案:将按键配置成外部中断源,当有按键按下,触发中断,在中断服务程序(isr)中去完成点灯。
我们用按键作为外部中断源,我们把按键对应的gpio配置成中断引脚,当按键按下,相应的gpio产生了电平跳变,就会触发外部中断。
3.3.2 外部中断示例 我们想达到按下按键灯亮, 松开按键灯灭这种效果(配成双边沿触发,按下的时候产生下降沿中断,进行点亮,松开产生上升沿中断,进行熄灭)。当然也可做成按一下点亮,再按一下熄灭的效果(设成单边沿触发,每来一次中断,对led电平进行一次取反)。
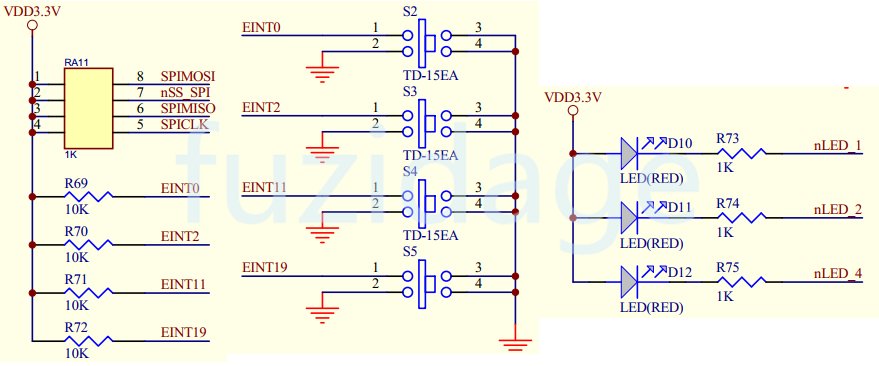
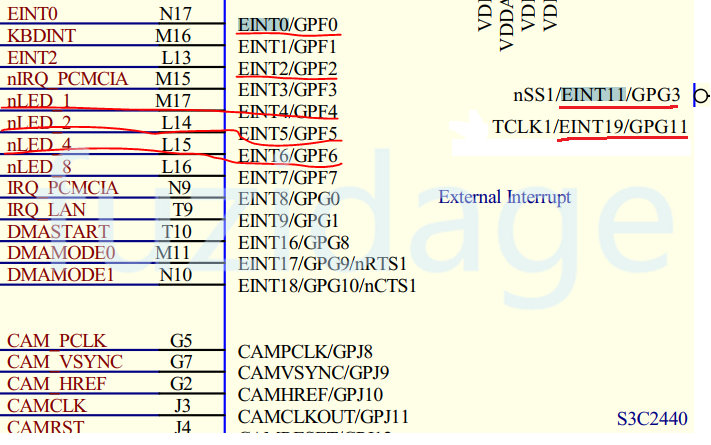
从按键的原理图中得知,当按键没有按下时,接上拉电阻,按键为高电平状态。当按键按下时,电位被拉低,按键处于低电平状态。s2-s5分别对应GPF0,GPF2,GPG3,GPG11; D10-D12这3盏led所对应的gpio分别是GPF4,GPF5,GPF6。
那么我们让s2,s3,s4分别控制D10,D11,D12;s5对D10-D12同时控制(按下s5同时点亮3个led)。
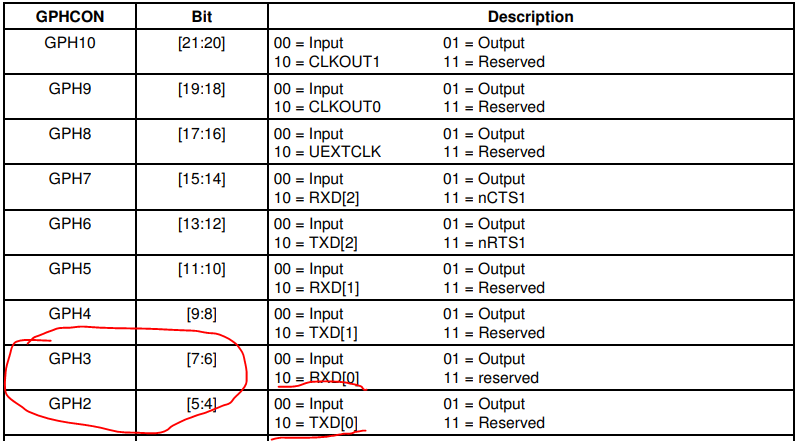
3.3.1.1 配置GPIO和中断源 配置D10-D12的gpio为输出模式,s2-s4的gpio为外部中断模式。
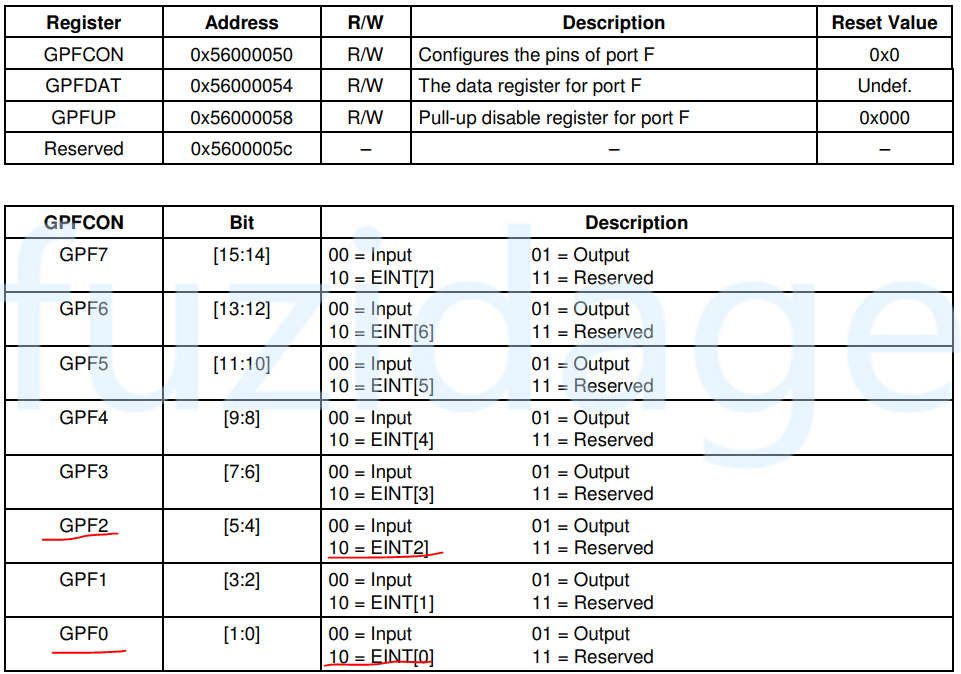
打开芯片手册找到第九章 IO ports,找到对应的gpio控制寄存器,将对应的gpio配置成中断模式。
配置GPF GPIO为中断引脚:
1 2 3 4 5 GPFCON &= ~((3 <<0 ) | (3 <<4 )); GPFCON |= ((2 <<0 ) | (2 <<4 )); GPGCON &= ~((3 <<6 ) | (3 <<22 )); GPGCON |= ((2 <<6 ) | (2 <<22 ));
设置中断触发方式:
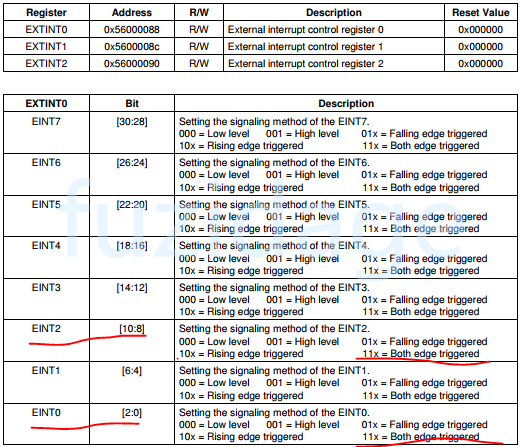
当电平从高变低时,此时表示按键按下,当电平由低变高,表示松开按键。不妨设置中断方式为双边沿触发,按下按键,触发下降沿中断,中断服务程序就可以去点亮led,反之,松开触发上升沿中断,就可以去熄灭led。
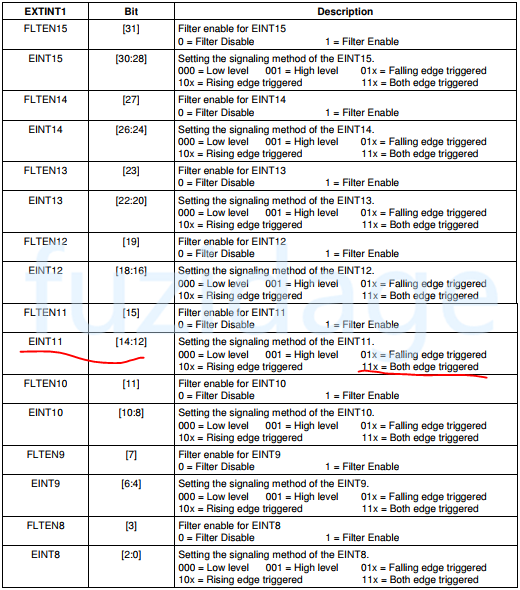
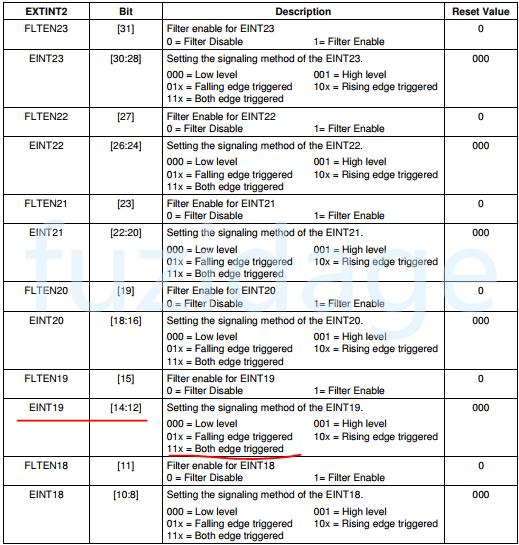
1 2 3 EXTINT0 |= (7 <<0 ) | (7 <<8 ); EXTINT1 |= (7 <<12 ); EXTINT2 |= (7 <<12 );
设置外部中断屏蔽寄存器EINTMASK:
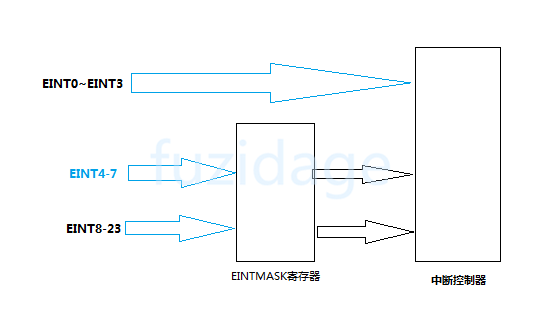
从上图我们知道外部中断0-3是直接连接到中断控制器,而外部中断4-7、外部中断8-23还要经过EINTMASK,那么我们需要配置EINTMASK来打开中断的通道:
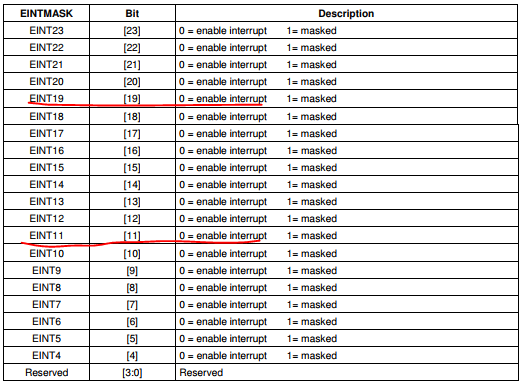
1 EINTMASK &= ~((1 <<11 ) | (1 <<19 ));
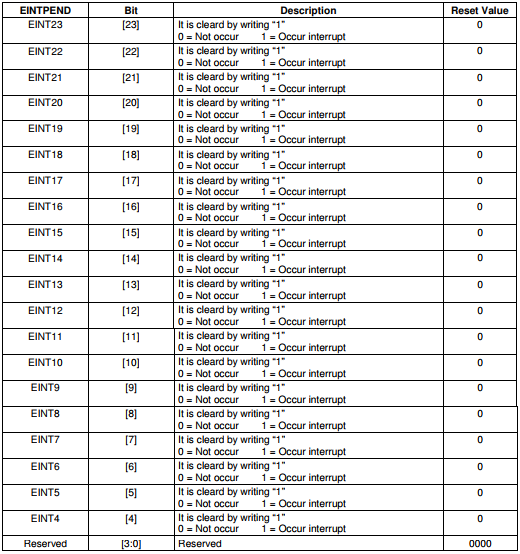
外部中断挂起寄存器EINTPEND:
当一个外部中断(EINT4-EINT23)发生后,那么相应的位会被置1, 所以中断结束后需要清除对应位。这个寄存器可以用来区分外部中断4-23的哪一个中断源。
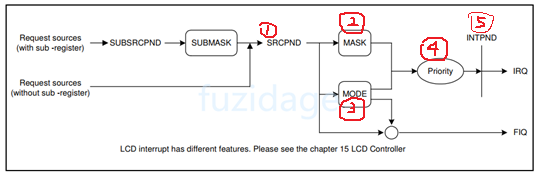
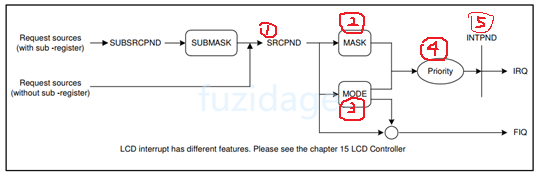
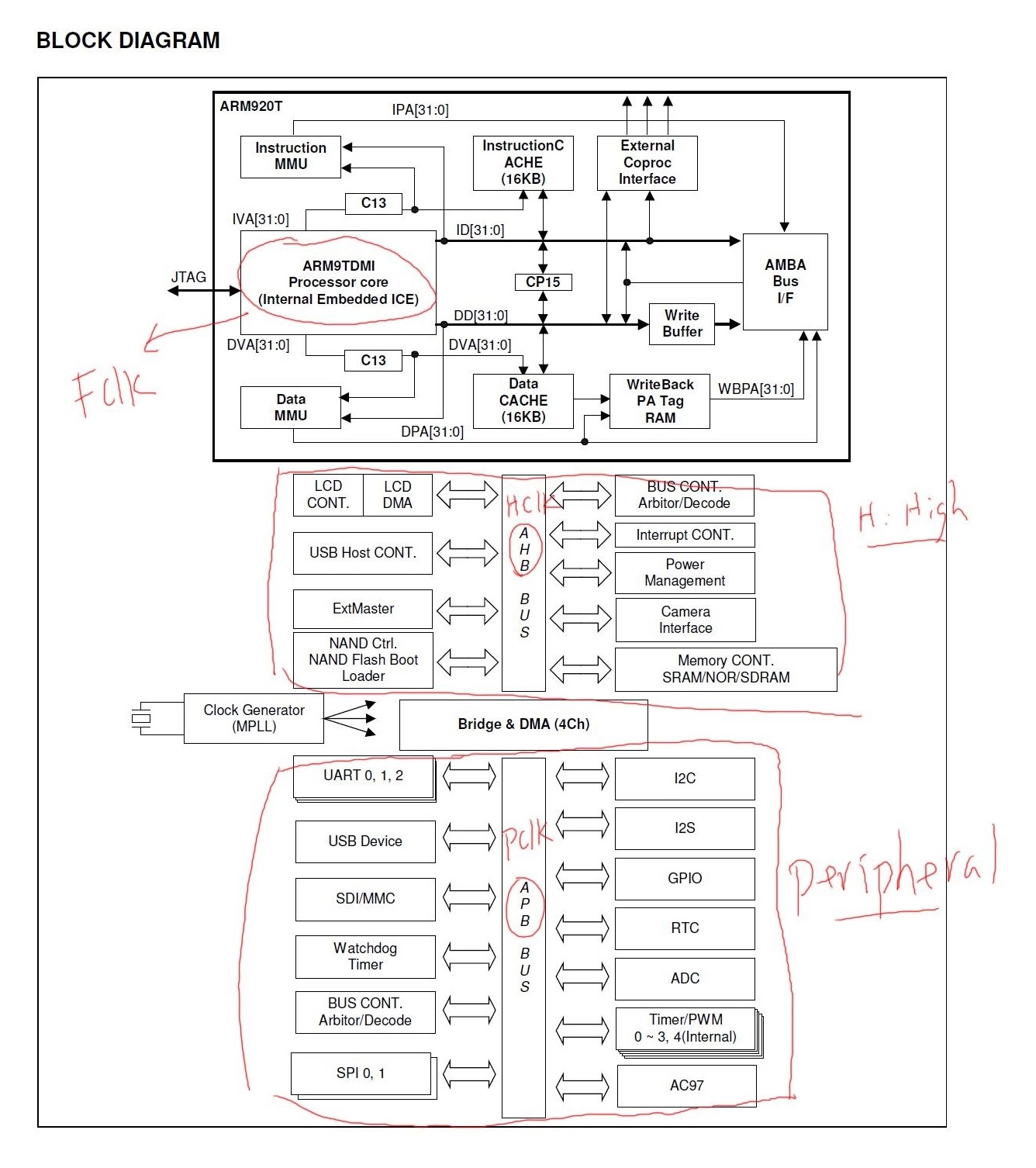
3.3.3.2 中断控制器设置 我们先来看下中断控制器的总框图:
1. 首先是SRCPND:用来表示哪个中断源发出了中断请求。
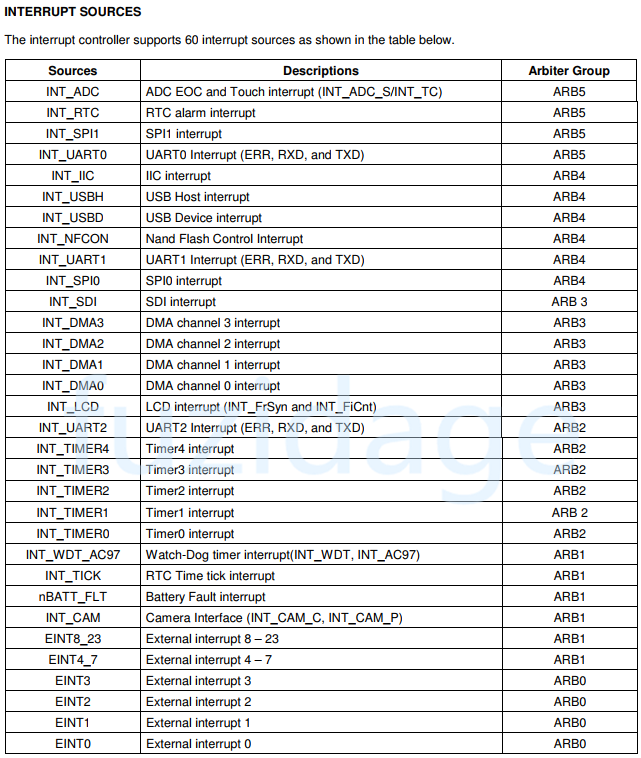
先看下中断源:
从上图我们发现外部中断有24个外部中断,除了外部中断EINT,还有定时器中断,ADC中断,UART中断等…。
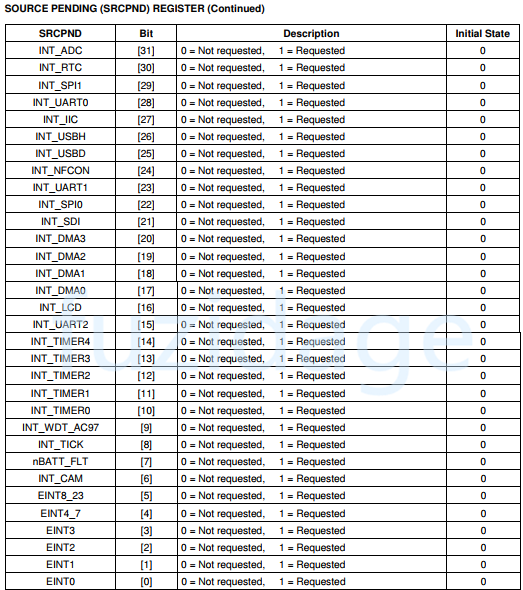
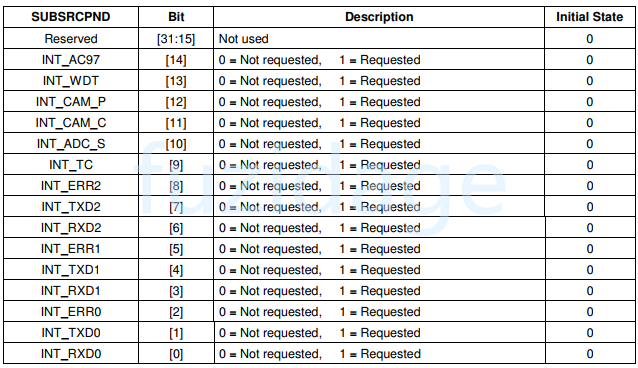
我们来认识下SRCPND寄存器:(用来表示哪个(哪些)中断源已产生中断请求,中断结束后要清中断)
从上图中我们发现EINT4-7共用1bit,EINT8-23共用1bit,那么肯定有其他寄存器来区分它们,那就是EINTPEND寄存器(后面5会讲)。
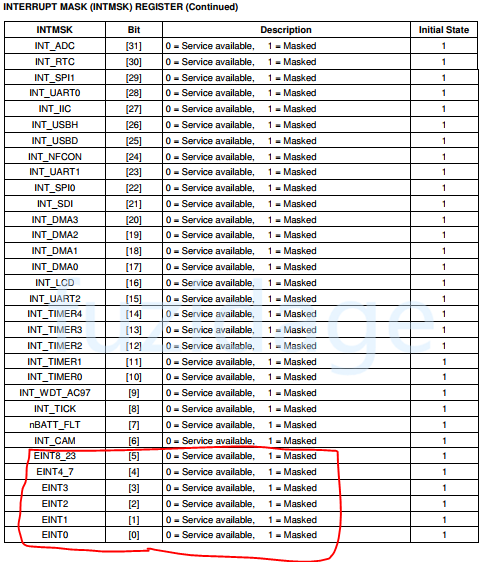
2. 然后到达INTMSK:(中断屏蔽寄存器)
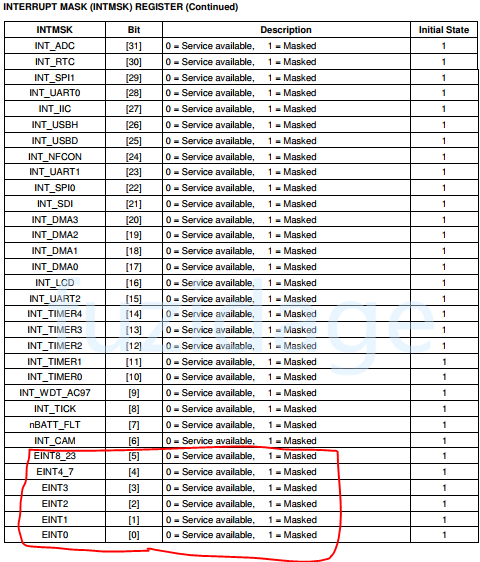
我们需要把INTMSK寄存器配置成非屏蔽状态,默认是中断源时屏蔽的,见下图:
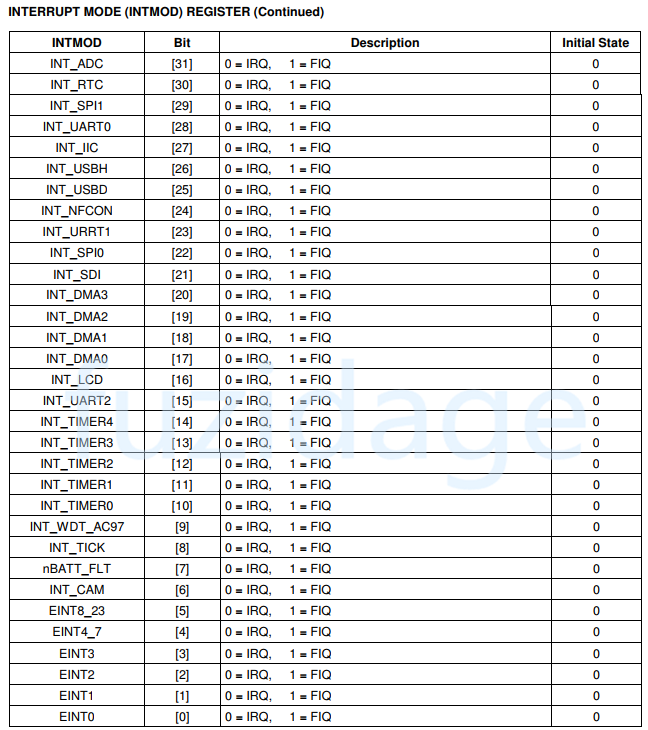
3.INTMOD(中断模式,是fiq还是irq)
4.Priroty:
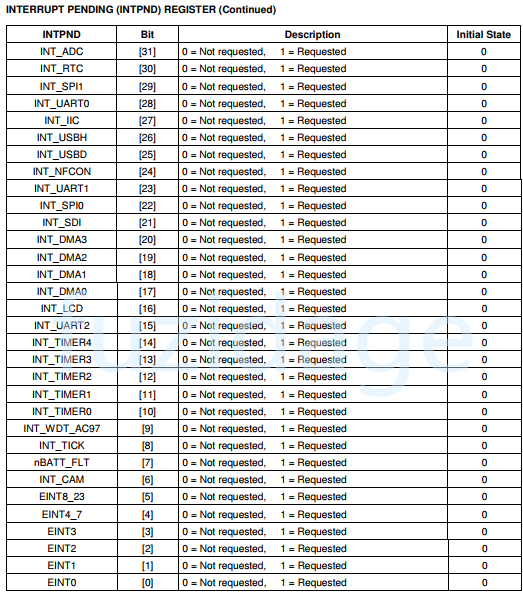
5.INTPND:
中断发生后,SRCPND中会有bit置1,可能好几个(因为同时可能发生几个中断),这些中断会由优先级仲裁器选出一个最紧迫的,然后把INTPND中相应位置1。所以只有INTPND置1,CPU才会处理。
我们知道有可能同时出现多个中断请求,那么INTPND就挑选出当前优先级最高的、正在发生的中断。
当产生irq后,要去分辨是哪个中断源,根据不同的中断源去中断服务程序isr中做不同的事情,那么如何得知当前产生的中断是哪一个外部中断源产生的呢?那么就可以访问这个INTPND寄存器。
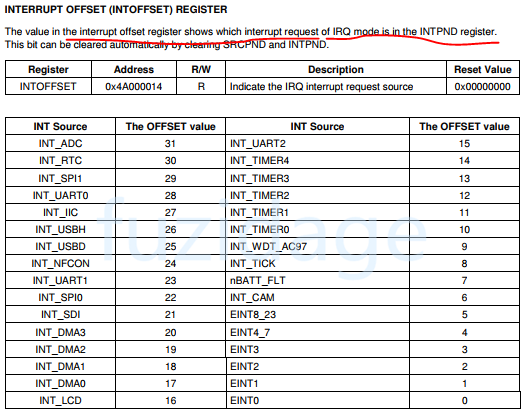
可是我们要去手工去解析INTPND里面的位,才能知道是哪个中断源产生了中断请求。那么有没有什么比较快捷的方式自动帮我们解析INTPND呢,直接返回中断号给我们?
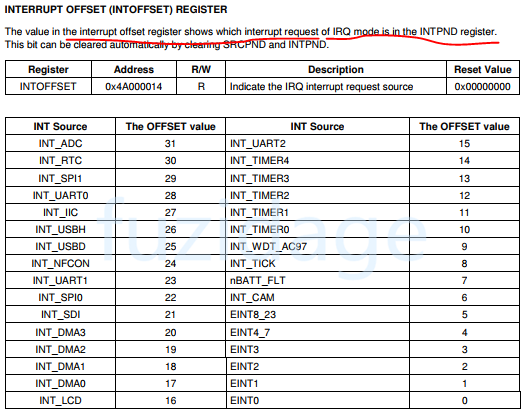
当然有啦,有一个INTOFFSET寄存器的值就是代表哪个中断请求产生了,如果INTOFFSET=0表示EINT0产生了中断请求,INTOFFSET=2表示EINT2产生了中断请求。具体见下图:
我们从上图看到ENIT4-7共用一个offset, EINT8-23也共用一个offset,那么要通过访问EINTPEND寄存器来区分它们。
中断控制器设置代码入下:
1 2 3 4 5 6 void interrupt_init (void ) { INTMSK &= ~((1 <<0 ) | (1 <<2 ) | (1 <<5 )); }
3.3.3.3 中断总开关
CPSR有I位,是irq的总开关,我们需要把CPSR寄存器 bit7给清零,这是中断的总开关,如果bit7设置为1,CPU无法响应任何中断。
1 2 3 bic r0, r0, #(1 <<7 ) msr cpsr, r0
3.3.3.4 中断服务程序 到这里中断前的初始化工作知识点就已经讲完了,当然要提前准备好led初始化工作(就是将led对应的gpio配置成输出模式,这个不讲解)。
那么中断产生后,我们之前讲过,会跳转到0x18异常向量,执行跳转指令ldr pc, =_irq,和之前的swi异常,und异常框架一样。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 .text .global _start _start: b reset ldr pc, und_addr ldr pc, swi_addr b halt b halt b halt ldr pc, irq_addr b halt und_addr: .word do_und swi_addr: .word do_swi irq_addr: .word do_irq reset: bic r0, r0, #(1 <<7 ) msr cpsr, r0 ldr pc, =main halt: b halt
1.我们在start.s中用汇编代码设置cpsr的I位,开启中断开关;
2.在main函数中初始化中断源key_eint_init,初始化中断控制器interrupt_init;
3.然后继续执行main主函数。
4.当中断产生,触发irq异常,进入0x18异常向量,执行do_irq。
do_irq实现如下(和do_und, do_swi类似):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 do_irq: ldr sp, =0x33d00000 sub lr, lr, #4 stmdb sp!, {r0-r12, lr} bl handle_irq_c ldmia sp!, {r0-r12, pc}^
handle_irq_c函数实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 void key_eint_irq (int irq) { unsigned int val = EINTPEND; unsigned int val1 = GPFDAT; unsigned int val2 = GPGDAT; if (irq == 0 ) { if (val1 & (1 <<0 )) { GPFDAT |= (1 <<6 ); } else { GPFDAT &= ~(1 <<6 ); } } else if (irq == 2 ) { if (val1 & (1 <<2 )) { GPFDAT |= (1 <<5 ); } else { GPFDAT &= ~(1 <<5 ); } } else if (irq == 5 ) { if (val & (1 <<11 )) { if (val2 & (1 <<3 )) { GPFDAT |= (1 <<4 ); } else { GPFDAT &= ~(1 <<4 ); } } else if (val & (1 <<19 )) { if (val2 & (1 <<11 )) { GPFDAT |= ((1 <<4 ) | (1 <<5 ) | (1 <<6 )); } else { GPFDAT &= ~((1 <<4 ) | (1 <<5 ) | (1 <<6 )); } } } EINTPEND = val; } void handle_irq_c (void ) { int bit = INTOFFSET; if (bit == 0 || bit == 2 || bit == 5 ) { key_eint_irq(bit); } SRCPND = (1 <<bit); INTPND = (1 <<bit); }
3.4 irq-定时器中断 3.4.1 引入看门狗定时器 s3c2440共有2种定时器:
1.Watchdog看门狗定时器
2.PWM脉冲可调制定时器
下面详细介绍2种定时器的原理,来了解定时器是如何产生定时器中断的。
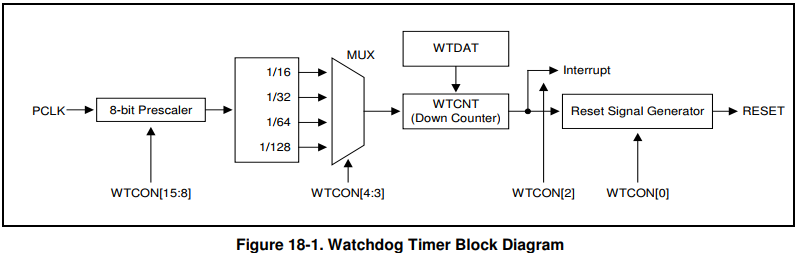
3.4.1.1 WatchDog定时器原理 Watchdog定时器的原理很简单,寄存器很少,框图如下:
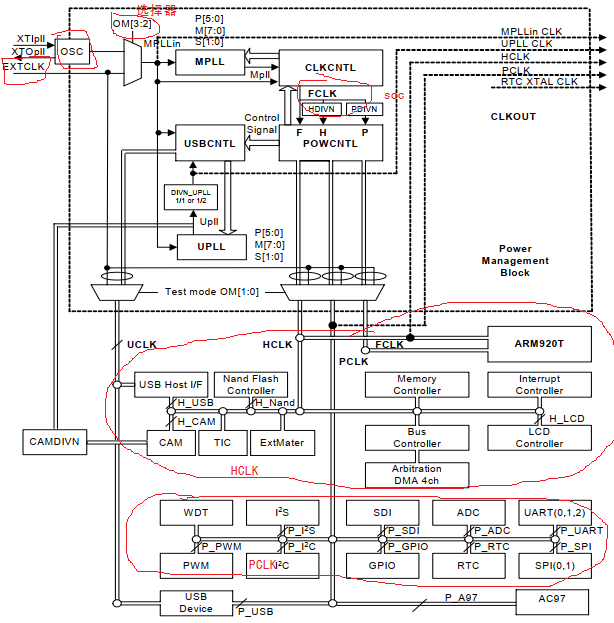
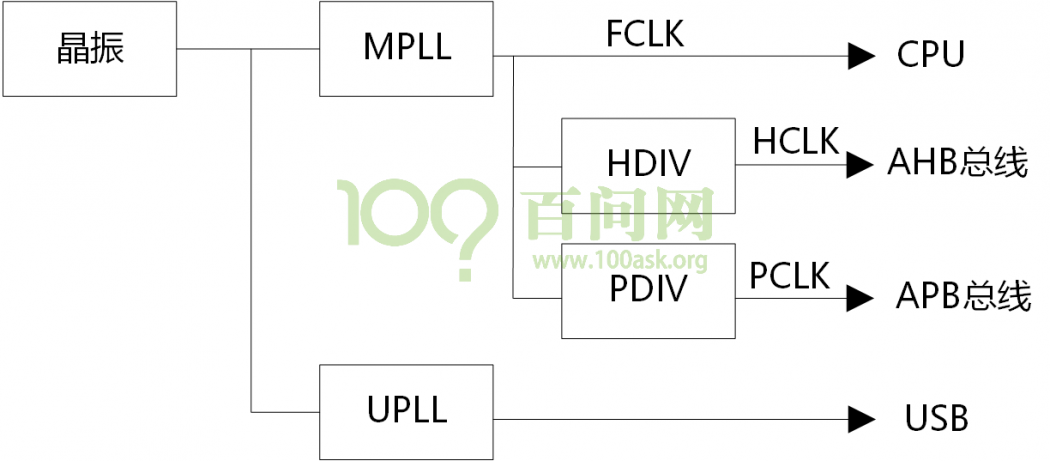
定时器,定时器那肯定是需要用到时钟的,从框图中可以看到Watchdog定时器采用的时钟源是PCLK,从s3c2440时钟体系 中也可以体现出来,接的是APB总线。
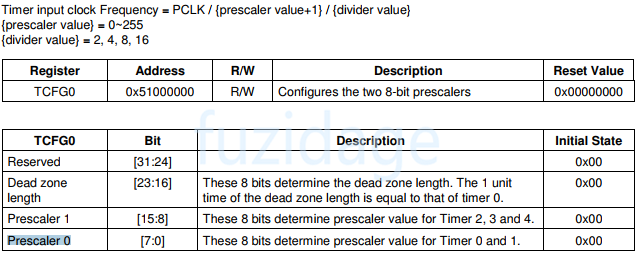
然后到达一个8 bit的分频器,可以通过配置WTCON[15:8]来设置分频器的预设值。
再设置WTCON[4:3]来设置除数因子来进一步分频。t_watchdog = 1/[ PCLK / (Prescaler value + 1) / Division_factor ]
到达WTCNT:看门狗递减寄存器。WTCNT里的数据就开始在输入时钟频率下递减。WTCNT的值由WTDAT寄存器提供。
WTDAT:WTDAT寄存器用于指定计数器的初始值,也就是它的超时时间,系统上电之后硬件自动的将0x8000的初始值载入到WTCNT里,在发生了第一次超时操作时,WTDAT的值才会载入到WTCNT寄存器 。
当WTCNT的值减到0时,就会触发看门狗定时器中断,进而产生复位。中断框图中可以看到可以设置WTCON[2]来设置是否产生中断信号,可以设置WTCON[0]来设置是否产生复位信号。
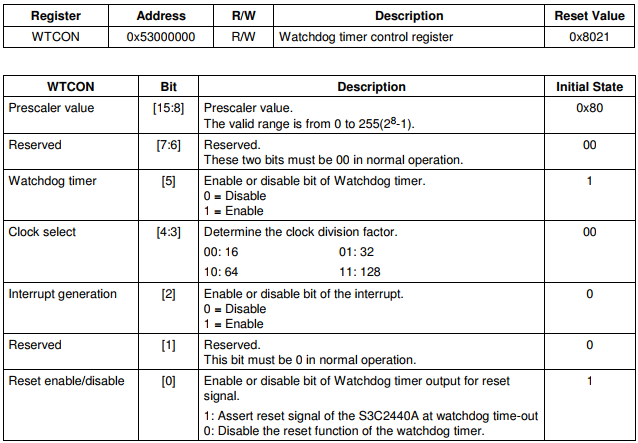
3.4.1.1.1 WTCON寄存器
3.4.1.1.2 WTCNT、WTDAT寄存器
3.4.2 WatchDog定时器中断示例 3.4.2.1 定时器初始化 在之前的章节中,我们在start.s启动代码中首先做的就是关闭看门狗,把WTCON[5]=0,也就是把Watchdog timer给disable。那么Watchdog Timer就不再工作了,这样做是为了防止在启动代码进行硬件初始化的时候出现超时,发出复位信号又去重启硬件,这样就陷入了不断重启过程中。因为s3c2440芯片默认WTCON[5]是1,也就是Watchdog Timer默认是处于使能状态。
从s3c2440时钟体系 中配置了PCLK=50M Hz, 那么让WTDAT取默认值0x8000,那么根据公式算出从开机到触发复位重启的时间:
t=WTDAT*( 1/[ PCLK / (Prescaler value + 1) / Division_factor ])。
根据WTCON寄存器配置Prescaler value=255,配置Division_factor=128,这样最终定时器分得的频率更低,那么减数器递减的更慢,也就代表从开机到触发复位重启的时间:
T=0x8000 * (1/[50*10^6/(255+1)/128]) = 21474836.48us = 21s。
之前的start.s中把看门狗已经关闭了,那么我们在跳转到main函数中调用wtd_timer_init函数实现如下:
1 2 3 4 void wtd_timer_init (void ) { WTCON |= (1 <<0 ) | (1 <<5 ); WTCON |= (3 <<3 ) | (255 <<8 ); }
我们查看测试结果:
现在修改代码如下:
1 2 3 4 5 void wtd_timer_init2 (void ) { WTCON |= (1 <<0 ) | (1 <<2 ); WTCON |= (3 <<3 ) | (255 <<8 ); WTDAT = 0x4000 ; }
我们看到我们现在定时器的初值被修改成了0x4000, 相对于默认值少了一半,那么触发wtd_timer中断的时间应该减半,也就是约等于10s。
3.4.2.2 定时器中断服务程序 那么需要写一个wtd_timer的中断服务程序,同样需要先在do_irq中去保护现场、调用handle_irq_c、恢复现场。查看INTOFFSET寄存器:
得知:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 void handle_irq_c (void ) { int bit = INTOFFSET; if (bit == 0 || bit == 2 || bit == 5 ) { key_eint_irq(bit); } else if (bit == 9 ) { 这里还需区分子中断源 } SRCPND = (1 <<bit); INTPND = (1 <<bit); }
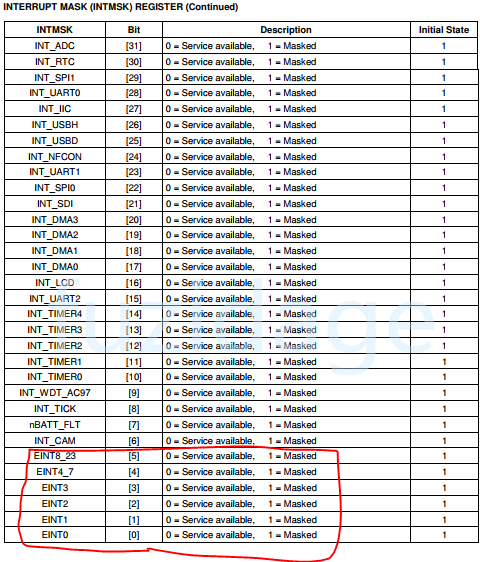
查看芯片手册查找“INT_WDT_AC97”如下图:
从上图可以看到SRCPND和SUBSRCPND的映射关系。
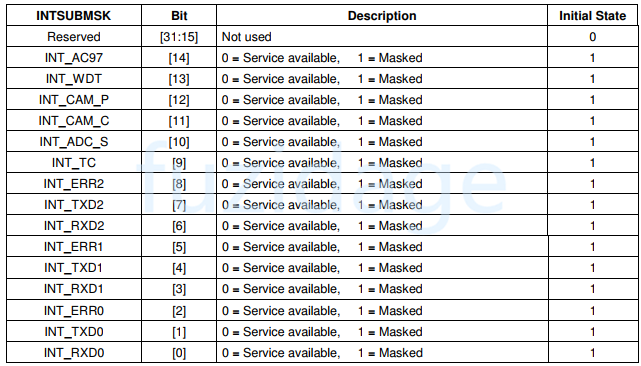
我们可以读取SUBSRCPND来区分到底是哪一个子中断源产生了中断,当SUBSRCPND中哪一位被置1,表示对应的中断源发生了中断。
前面做完wtd_timer_init,还要进行中断控制器的初始化,查看INTMSK寄存器如下图:
查看INTSUBMSK寄存器如下图:
在interrupt_init中添加:
1 2 INTMSK &= ~(1 <<9 ); INTSUBMSK &= ~(1 <<14 );
修改handle_irq_c:
1 2 3 4 5 6 7 8 9 ... else if (bit == 9 ){ if (SUBSRCPND & 1 <<14 ) { printf ("watchdog timer interrupt occured.\n" ); } } ...
3.4.3 PWM脉冲宽度调制定时器 PWM(Pulse Width Modulation),字面上是脉冲可调制的意思,就是可以调节占空比。
s3c2440有5个定时器,其中定时器0、1、2和3具有脉宽调制(PWM)功能。定时器4是一个无输出引脚的内部定时器。
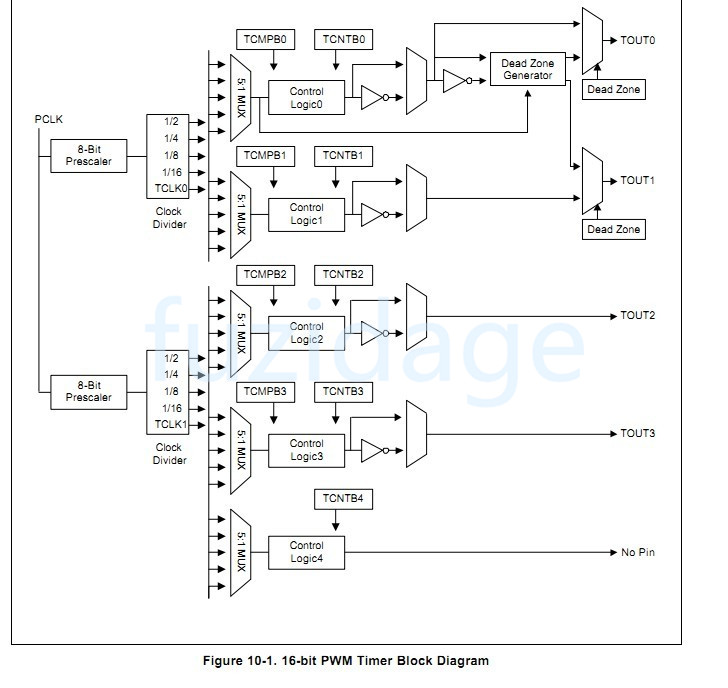
先认识下s3c2440的pwm timer的框架:
1.时钟源为PCLK
2.pclk经过8 bit的预分频系数(Prescaler),和4 bit的时钟除数因子(clock divider),进行分频
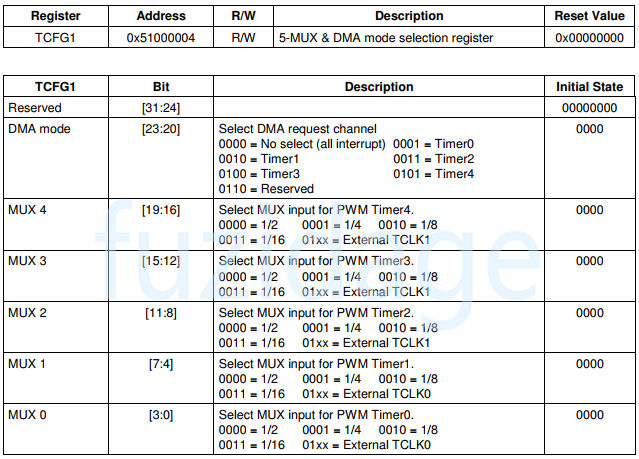
3.经过MUX选择器选择用哪个定时器(5选1)
4.设置TCMPB0和TCNTB0和TCONn寄存器
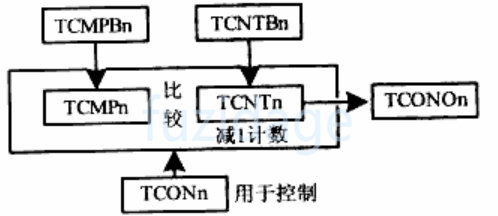
3.4.1.1 pwm定时器原理 pwm定时器的逻辑控制单元结构如下:
1 2 3 4 5 1 TCMPBn和TCNTBn寄存器中的值分别加载到TCMPn和TCNTn寄存器2 每来一个clk(时钟)这个TCNTn减去1 3 当TCNTn == TCMPn时,可以产生中断,pwm输出引脚反转4 TCNTn继续减1 ,当TCNTn == 0 时,又产生一次中断,pwm引脚再次反转5 重复1 -4 过程
设置TCNTBn寄存器来设置加载初值,设置后TCNTn中的值就会按照时钟周期递减。
3.4.3.2 pwm定时器编程实现 要开始一个PWM定时器功能的步骤如下:(假设使用的是timer0)
3.4.3.2.1 初始化pwm定时器 定义一个pwm_timer_init()函数。
设置时钟:
分别设置定时器0的预分频器值(prescaler)和时钟分频值(clock divider),从而控制TCNT0减数器的频率。
根据公式:
1 pwm Timer clk = PCLK / {(预分频数)prescaler value+1 } / {divider value(5.1 MUX值)}
PCLK是50M,设置prescaler value=99, divider value=16,所以pwm Timer clk= 50000000/(99+1)/16 = 31250 Hz
1 2 3 TCFG0 = 99 ; TCFG1 &= ~0xf ; TCFG1 |= 3 ;
设置初值:
1 2 3 TCNTB0 = 31250 << 1 ; TCMPB0 = 31250 >> 1 ;
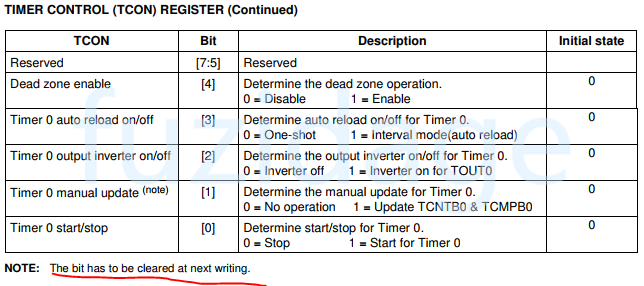
开启定时器0的手动更新TCNTB0&TCMPB0功能(设置TCON的第1位):
开启定时器0的自动加载:
1 2 TCON &= ~(1 <<1 ); TCON |= (1 <<3 );
启动定时器0(设置TCON的第0位);
初始化中断控制器:
1 2 3 4 5 interrupt_init(){ ... INTMSK &= ~(1 <<10 ); ... }
做完这些初始化工作,就可以产生定时器中断了,同样我们需要在handle_irq_c函数中区分中断源:
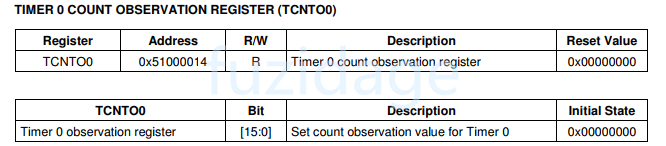
3.4.3.2.2 pwm定时器中断服务程序 我们可以通过查看TCNTO0寄存器来查看当前TCNT的值。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 void handle_irq_c (void ) { int bit = INTOFFSET; if (bit == 0 || bit == 2 || bit == 5 ) { key_eint_irq(bit); } else if (bit == 9 ) { ... } else if (bit == 10 ) { printf ("timer0 interrupt occured.\n" ); print_hex(TCNTO0); } SRCPND = (1 <<bit); INTPND = (1 <<bit); }
3.5 irq的优化改进 我们对比irq外部中断, irq定时器中断,发现每增加一个中断源,又要去修改中断控制器的初始化interrupt_init()和handle_irq_c(),要在handle_irq_c()中去添加分支去执行不同的中断服务。
那么我们现在不去改变interrupt文件,在timer.c、key_eint.c中去注册自己的中断服务程序即可,这里我们使用函数指针数组 ,建立一个中断号和中断服务程序的映射关系。这样就可以根据中断号来执行对应的中断服务程序,即在handle_irq_c()中去回调不同类型的中断源注册下来的函数即可。
1 2 3 4 #define IRQ_NUM 32 typedef void (*irq_func) (int ) ;irq_func irq_array[IRQ_NUM];
然后实现一个register_irq(…)如下:
1 2 3 4 5 void register_irq (int irq, irq_func fp) { irq_array[irq] = fp; INTMASK &= ~(1 << irq) }
handle_irq_c()修改实现如下:
1 2 3 4 5 6 7 8 9 10 11 void handle_irq_c (void ) { int bit = INTOFFSET; irq_array[bit](bit); SRCPND = (1 <<bit); INTPND = (1 <<bit); }
这样子我们的irq中断就被统一管理了起来,只要在其他各中断模块初始化的时候调用register_irq(…)注册即可。