1 中断与异常种类#
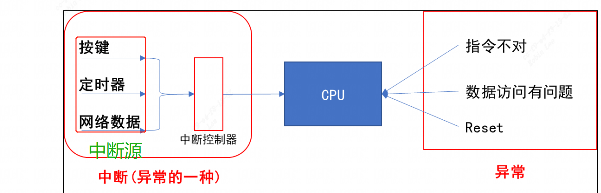
CPU 在运行的过程中,也会被各种“异常”打断。这些“异常”有:
- 指令未定义
- Reset复位
- 指令、数据访问有问题
- SWI(软中断)
- 快中断
- IRQ中断
IRQ中断只是一种(一类)异常而已。导致中断发生的情况有很多,比如:
- 按键
- 定时器
- ADC 转换完成
- UART 发送完数据、收到数据
这些众多的“中断源”,汇集到“中断控制器”,由“中断控制器”选择优先级最高的中断并通知 CPU。如上图所示:
2 中断的处理流程#
arm 对异常(中断)处理过程:
- 初始化:
a) 设置中断源,让它可以产生中断
b) 设置中断控制器(可以屏蔽某个中断,优先级)
c) 设置 CPU 总开关(使能中断) - 执行其他程序:正常程序
- 产生中断:比如按下按键(中断源发出中断请求)—>中断控制器—>CPU
- CPU 每执行完一条指令都会检查有无中断/异常产生
- CPU 发现有中断/异常产生,开始处理。
对于不同的异常,跳去不同的地址执行程序。这地址上,只是一条跳转指令,跳去执行某个函数(地址),这个就是异常向量。③④⑤都是硬件做的。③是中断源来做,④⑤是cpu来做
综上5个过程,软件要做的事情:
a) 保存现场(各种寄存器)
b) 处理异常(中断): 从异常向量表跳到不同的异常向量去执行,分辨中断源,再调用不同的处理函数
c) 恢复现场
2.1 异常向量表#
可以参考我之前写的s3c2440裸机-异常中断(一. 异常、中断的原理与流程) 介绍了异常向量表。
uboot中就有大量类似这种的异常向量表,不同系列芯片每个异常的偏移地址会有所不同。下图以s3c2440芯片为例: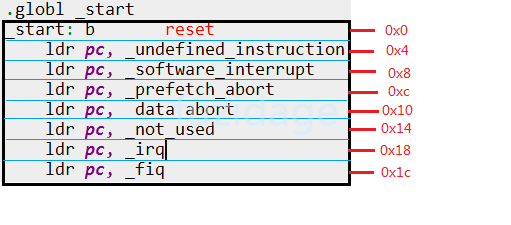
| 向量地址 | 中断类型 | 中断模式 |
|---|---|---|
| 0X00 | 复位中断(Rest) | 特权模式(SVC) |
| 0X04 | 未定义指令中断(Undefined Instruction) | 未定义指令中止模式(Undef) |
| 0X08 | 软中断(Software Interrupt,SWI) | 特权模式(SVC) |
| 0X0C | 指令预取中止中断(Prefetch Abort) | 中止模式 |
| 0X10 | 数据访问中止中断(Data Abort) | 中止模式 |
| 0X14 | 未使用(Not Used) | 未使用 |
| 0X18 | IRQ | 中断(IRQ Interrupt) |
| 0X1C | FIQ | 中断(FIQ Interrupt) |
这就是异常向量表,每一条指令对应一种异常。
发生复位时,CPU 就去 执行第 1 条指令:b reset。
发生中断时,CPU 就去执行“ldr pc, _irq”这条指令。这些指令存放的位置是固定的,比如对于ARM9芯片中断向量的地址是0x18。当发生中断时,CPU 就强制跳去执行 0x18 处的代码。
2.1.1 中断向量表偏移(vector base)#
在向量表里,一般都是放置一条跳转指令,发生该异常时,CPU 就会执行向量表中的跳转指令,去调用更复杂的函数。当然,向量表的位置并不总是从 0 地址开始,很多芯片可以设置某个 vector base 寄存器,指定向量表在其他位置,比如imx6ull芯片设置 vector base 为 0x80000000,指定为 DDR 的某个地址。但是表中的各个异常向量的偏移地址,是固定的:复位向量偏移地址是 0,中断是 0x18。
2.2 GIC概述#
对于 ARM 的中断控制器,述语上称之为 GIC (Generic Interrupt Controller),到目前已经更新到 v4 版本了。在STM32叫做NVIC(内嵌向量中断控制器 Nested Vectored Interrupt Controller)
简单地说,GIC v3/v4 用于 ARMv8 架构,即 64 位 ARM 芯片。
而 GIC v2 用于 ARMv7 和其他更低的32位架构。v2架构下一节:设备驱动-10.中断子系统-5 armv7 GIC架构解析 会展开细说。
v8架构是在32位ARM架构上进行开发的,将被首先用于对扩展虚拟地址和64位数据处理技术有更高要求的产品领域,如企业应用、高档消费电子产品。ARMv8架构包含两个执行状态:AArch64和AArch32。AArch64执行状态针对64位处理技术,引入了一个全新指令集A64;而AArch32执行状态将支持现有的ARM指令集。
2.3 保护现场,恢复现场的核心:栈#
中断当前正在运行的进程、线程。进程、线程是什么?内核如何切换进程、线程、中断?要理解这些概念,必须理解栈的作用。
进程是资源分配的基本单位,线程是调度的基本单位。
比如全局变量a, 对不同线程它是共享的,但是这个资源a是属于该进程独立的资源,对其他进程是不可见的。
一个进程可以包含多个线程,线程有自己的栈空间,也就是局部变量。
2.3.1 ARM 处理器程序运行的过程#
ARM 芯片属于精简指令集计算机(RISC:Reduced Instruction Set Computing),它所用的指令比较简单,有如下特点:
对内存只有读、写指令
对于数据的运算是在 CPU 内部实现
使用 RISC 指令的 CPU 复杂度小一点,易于设计
比如对于a=a+b这样的算式,需要经过下面 4 个步骤才可以实现: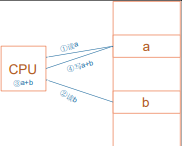
我们先忽略各种 CPU 模式(系统模式、用户模式等等)。详细过程如下: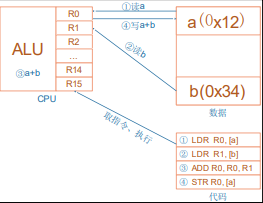
1 | LDR R0, [a] |
2.3.2 入栈保护现场/出栈恢复现场#
当进行函数调用跳转到下一个函数,又或者中断一个程序,就需要把这些寄存器的值保存下来:这就称为保存现场。保存的寄存器那块内存就称为栈空间。
当跳转的函数执行完成,就需要从栈中恢复那些 CPU 内部寄存器的值,这一出栈的过程也被叫做“恢复现场”。
①函数调用:
1.在函数 A 里调用函数 B,实际就是中断函数 A 的执行。
2.那么需要把函数 A 调用 B 之前瞬间的 CPU 寄存器的值,保存到栈里
②中断处理:
a) 进程 A 正在执行,这时候发生了中断。
b) CPU 强制跳到中断异常向量地址去执行,
c) 这时就需要保存进程 A 被中断瞬间的 CPU 寄存器值,
d) 可以保存在进程 A 的内核态栈,也可以保存在进程 A 的内核结构体中。
e) 中断处理完毕,要继续运行进程 A 之前,恢复这些值
③进程切换:
进程 A 的时间用完了,就切换到进程 B。怎么切换?切换过程是发生在内核态里的,跟中断的处理类似。
a) 进程 A 被切换瞬间的 CPU 寄存器值保存在某个地方;
b) 恢复进程 B 之前保存的 CPU 寄存器值,这样就可以运行进程 B 了。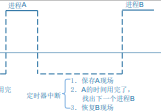
总结有3种场景会要用到栈去保存和恢复现场:
①函数调用,②进程切换,③中断过程。进程调度核心就是靠定时器中断来实现。
2.4 硬件中断、软件中断#
2.4.1 硬中断#
硬件产生的中断,称之为“硬件中断”(hard irq)。每个硬件中断都有对应的处理函数,比如按键中断、网卡中断,定时器中断的处理函数肯定不一样。
为方便理解,可以先认为对硬件中断的处理是用数组来实现的,数组里存放的是函数指针:一个中断号对应一个中断服务函数
2.4.2 软中断#
相对的,还可以人为地制造中断:软件中断(soft irq),如下图所示: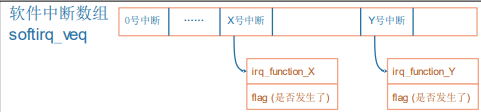
- 软件中断何时生产?
由软件决定,对于 X 号软件中断,只需要把它的 flag 设置为 1 就表示发生了该中断。 - 软件中断何时处理?
软件中断嘛,并不是那么十万火急,有空再处理它好了,因此一般软件中断是硬件中断处理完后,顺便来处理软件中断。 - 有哪些软件中断?
2.4.2.1 软中断的类型#
查内核源码 include/linux/interrupt.h
怎么设置使用软中断,比如tasklet (后面会讲中断上半部分, 和中断下半部分)就是使用软件中断实现的。还有字符设备驱动-8-内核定时器 字符设备驱动-9.内核定时器也是利用软中断实现的。
总结使用软中断的类型有:
1 | 优先级为0,HI_SOFTIRQ,高优先级的tasklet |
2.4.2.2 软件中断的API使用#
2.4.2.2.1 注册软中断-open_softirq#

1 | void open_softirq(int nr, void (*action)(struct softirq_action *)){ |
例如网络发包对应类型为NET_TX_SOFTIRQ的处理函数net_tx_action。
1 | // net/core/dev.c |
2.4.2.2.2 使能软中断-raise_softirq#

最核心的函数是 raise_softirq,简单地理解就是设置 softirq_veq[nr]的标记位,设置后表示使能该软中断号。
2.4.2.2.3 执行软中断-do_softirq#
每个 CPU 上会初始化一个 ksoftirqd 内核线程,负责处理各种类型的 softirq 中断事件:

当注册软中断使能后,ksoftirqd 线程,执行pending的软中断。ksoftirqd 里面会进一步调用到 __do_softirq。
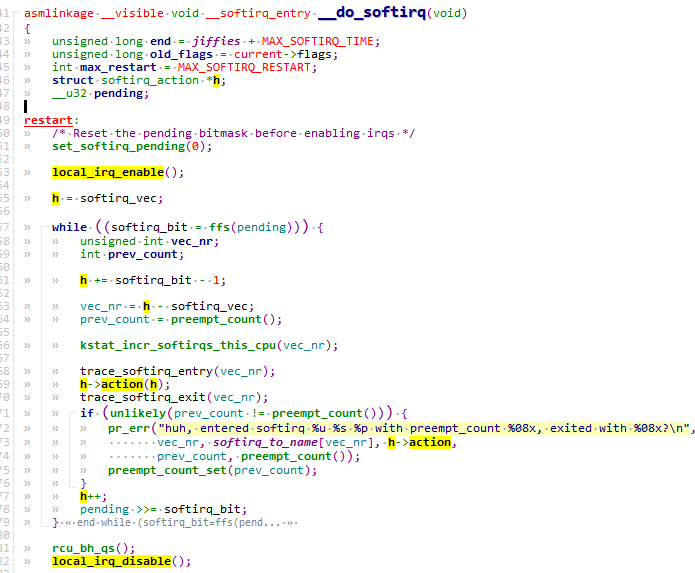
可以看到软中断执行,硬件中断是使能的。遍历使能的softlrq,执行对应的action函数。
2.4.3 硬件中断和软中断区别#
- 硬件中断包含gpio,网卡,外围电路IP等等,
tick(产生一次tick系统滴答中断,jiffies加1) - 软件中断包含
TIMER表示定时中断、RCU 表示 RCU 锁中断、SCHED表示内核调度中断

区别:
上半部直接处理硬件请求,也就是硬中断,主要是负责耗时短的工作,特点是快速执行;
下半部是由内核触发,也就说软中断,主要是负责上半部未完成的工作,通常都是耗时比较长的事情,特点是延迟执行
硬中断(上半部)是会打断 CPU 正在执行的任务,然后立即执行中断处理程序,而软中断(下半部)是以内核线程的方式执行
cat /proc/softirqs可以看软件中断信息
1 | $ cat /proc/softirqs |
cat /proc/interrupts可以看硬件中断
2.5 中断处理原则#
2.5.1 原则 1:不能嵌套#
中断 A 正在处理的过程中,假设又发生了中断 B,那么在栈里要保存 A 的现场,然后处理 B。在处理 B 的过程中又发生了中断 C,那么在栈里要保存 B 的现场,然后处理C。
如果中断嵌套突然暴发,那么栈将越来越大,栈终将耗尽。
为了防止这种情况发生,也是为了简单化中断的处理,在 Linux 系统上规定中断无法嵌套:即当前中断 A 没处理完之前,不会响应另一个中断 B(即使它的优先级更高)。
1 | local_irq_disable(); |
2.5.2 原则 2:越快越好#
在单核心芯片系统中,假设中断处理很慢,那应用程序在这段时间内就无法执行:系统显得很迟顿。
2.5.3 原则 3:耗时久的中断操作切分为中断上半部、下半部#
当处理某个中断要做的事情就是很多,没办法加快。比如对于按键中断,我们需要等待几十毫秒消除机械抖动。难道要在irq_handler 中等待吗?对于计算机来说,这可是一个段很长的时间。又比如图像处理中,当一个硬件IP处理完成一张图像的操作,那么对这张图像的后处理操作难道要放在中断服务中来操作嘛,显然这个耗时是非常久的。
那么中断操作切分为中断上半部、下半部。上半部分关中断,清中断执行关键紧急的事情,下半部分去处理耗时久的事情,如下图: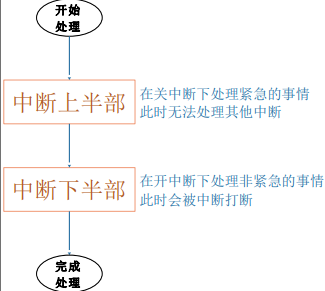
中断下半部的实现有很多种方法: ①tasklet(小任务)、②work queue(工作队列), ③threaded irq等。
2.5.4 原则 4:上半部和下半部均不能休眠#
中断上半部、下半部的执行过程中,不能休眠:中断休眠的话,以后谁来调度进程啊?
2.6 中断下半部处理方法#
2.6.1 小任务tasklet#
tasklet 是使用软中断来实现的:
中断上半部和下半部的处理流程: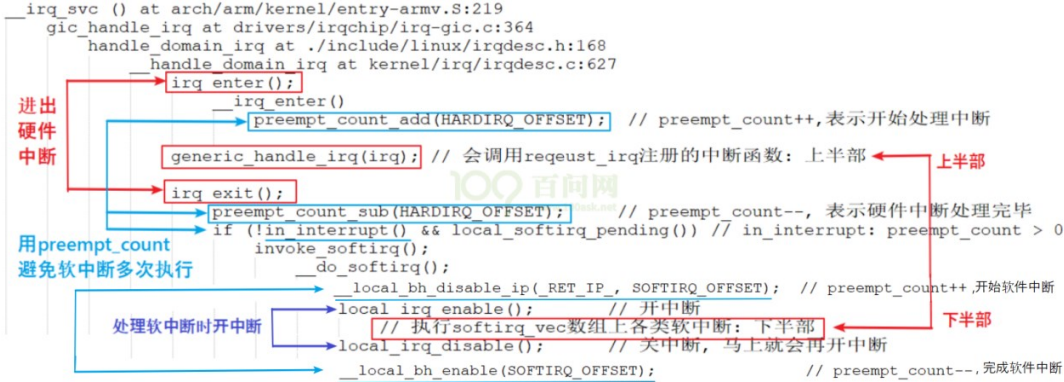
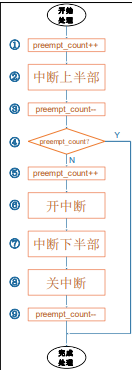
1 | 1. 中断源产生中断,执行irq_enter(), 最开始preempt_count=0,preempt_count++后为1, |
上半部中断(硬件中断)有local_irq_disable(),中断是不允许被另一个中断打断的。而下半部(软件中断)时中断是开的,它可以被其他中断打断local_irq_enable()。
那么软中断(下半部)A还没有执行到⑨preempt_count--,当被其他中断B打断时,又执行①preempt_count++,等于2,又进入了下一个硬件中断B流程。当下一个硬件中断B流程执行完后,preempt_count--,等于1,此时不会进入软总断流程直接结束,然后恢复A中断的下半部,继续执行完A中断下半部分的代码。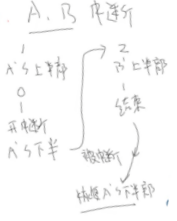
那这样B的下半部怎么执行呢?难道不要了吗?注意:步骤7中的中断下半部处理过程中,它处理的是所有中断的下半部分,处理完A的下半部后会继续处理B中断的下半部。所以,多个中断的下半部,是汇集在一起处理的。
总结:
1 | 1.中断的处理可以分为上半部,下半部 |
2.6.2 工作队列workqueue#
如果下半部要做的事情太多,那么tasklet就有点不太符合需求了,我们希望建立一个线程来专门执行中断后处理,用内核线程来做:在中断上半部唤醒内核线程。
在linux操作系统中,有一个内核线程**kworker** 线程,是系统帮我们创建的。内核中有很多这样的线程: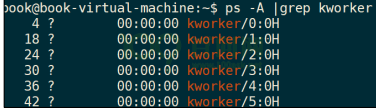
kworker 线程要去“工作队列”(work queue)上取出一个一个“工作”(work),来执行它里面的函数。
1.创建 work
2.要执行这个函数时,把 work 提交给 work queue 就可以了
上述函数会把 work 提供给**系统默认的 work queue:system_wq**,它是一个队列。schedule_work 函数不仅仅是把 work 放入队列,还会把kworker 线程唤醒。
3.什么时候把 work 提交给 work queue?
在中断场景中,可以在中断上半部调用 schedule_work 函数。
因此耗时久的中断下半部分,应该利用线程化处理方式,比如使用工作队列workqueue,上半部调用schedule_work 函数,触发 work 的处理。
2.6.3 threaded irq#

threaded_irq:下半部也是利用线程化处理。前面的workqueue处理使用方法太麻烦,需要在上半部进行work定义,schedule_work操作。
1 | 参数handler:上半部分可以为空 |
以前用 work 来线程化地处理中断,一个 worker 线程只能由一个 CPU 执行,多个中断的 work 都由同一个 worker 线程来处理,在单 CPU 系统中也只能忍着了。但是在 SMP 系统中,明明有那么多 CPU 空着,你偏偏让多个中断挤在这个CPU 上?
新技术 threaded irq,为每一个中断都创建一个内核线程;多个中断的内核线程可以分配到多个 CPU 上执行,这提高了效率。