1 ToolChain官方下载地址#
下载地址: https://releases.linaro.org/components/toolchain/binaries/4.9-2017.01/arm-linux-gnueabihf/
2 readelf#
2.1 elf格式#
elf是一种用于二进制文件、可执行文件、目标代码、共享库和核心转储格文件的文件格式。是UNIX系统实验室(USL)作为应用程序二进制接口(Application Binary Interface,ABI)而开发和发布的,也是Linux的主要可执行文件格式。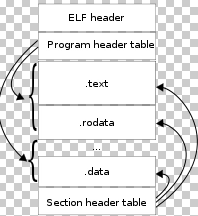
2.1.1 readelf命令#
readelf是一个读取elf格式的命令,比如下图是一个vmlinux原始elf文件,ARM 32bit LSB格式,使用静态库。使用readelf -h可以查看elf header信息。无论elf是什么格式,elf header只是描述头部信息,因此用什么工具链的命令都一样。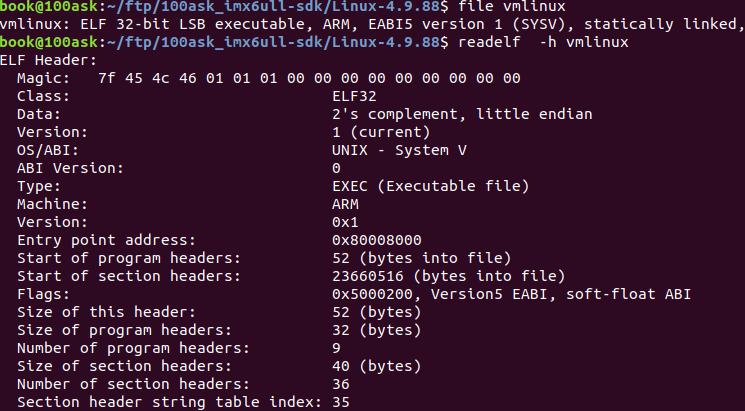
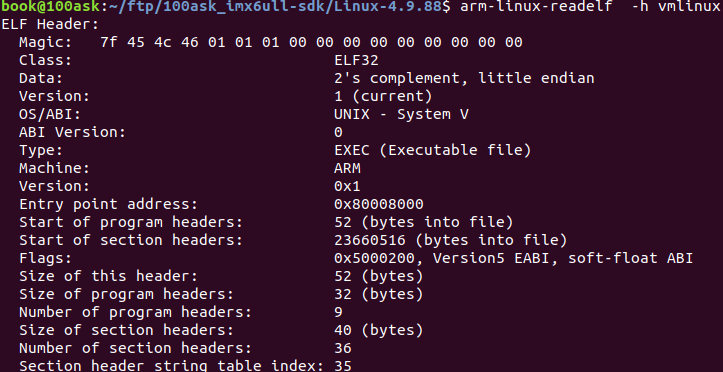
用hexdump看头部果然位7f 45 4c 46
再看Entry point address: 0x8000,8000这个表示加载入口点。
2.2 elf文件类型#
elf 文件通常有三种类型: ①可重定位目标文件 ②可执行文件 ③动态库
2.2.1 可重定位目标文件#
实际上就是在编译过程中生成的 .o 文件,或者是静态库文件。
elf头部:整个文件的描述+目录
sections:也就是我们经常提到的代码段、数据段所存放的位置。
section headers table:对文件中所有的段进行描述,段的起始地址,大小等信息
符号表以及字符串表: 注意这里的字符串表并不是应用程序中定义的字符串内容,而是编译时的一些符号字符串,比如 printf、main、.test、.bss 等
2.2.1.1 读头部#
1 | root@hd:~# readelf -h foo.o |
头部对应的C语言中结构体,这个结构体可以在 readelf 的源代码中找到:
1 | typedef struct { |
**e_ident(magic部分)**:
e_ident 是一个包含 16 字节的数组成员,对应 readelf -h 给出的 magic 部分,关于这一部分就需要参考 readelf 源码来进行分析了,分析结果如下:
1 | 前四个字节:7f 45 4c 46,识别码, 0x45,0x4c,0x46 三个字节的 ascii 码对应 ELF 字母,通过这四个字节就可以判断文件是不是 elf 文件. |
e_type(elf类型)
- 可重定位的目标文件
- 可执行文件
- 动态链接文件
- coredump 文件,这是系统生成的调试文件.
这四种类型的文件各有各的特点,比如可重定位的目标文件针对的是链接器.
而可执行文件针对加载器,需要被静态加载到内存中执行,而动态链接文件则是运行过程中的加载.
e_machine(机器架构)
标识指定的机器,比如 40 代表 ARM.
e_entry(程序入口虚拟地址)
程序的入口虚拟地址,对于可重定位的目标文件默认是0,而对于可执行文件而言是真实的程序入口.
程序入口是被加载器使用的,在程序加载过程中会读取该程序入口,作为应用程序的开始执行地址,在实际的加载过程中,内核加载完当前 elf 可执行文件之后其实并不是跳到该入口地址,而是先执行动态链接器代码,在动态链接完成之后才会跳到该入口地址。
e_phoff
四个字节的 program headers 的起始偏移地址
e_shoff
四个字节的 section headers 的起始偏移地址
e_ehsize
指示 elf header 的 size,对于 arm 而言,52 或者 64.
2.2.1.2 读section#
1 | readelf -S foo.o |
一共10个段。
2.2.2 可执行文件#
可执行文件是给加载器使用,而可重定位目标文件是给链接器使用。
2.2.2.1 读头部#
1 | readelf -h foo |
和2.2.1 可重定位目标文件对比,有以下几点不同:
- Type 由 REL (Relocatable file) 变成了 EXEC (Executable file),表示这是一个可执行文件.
- Entry point address,即程序入口为 0x82e1 而不再是 0,表示程序在加载时需要将入口代码放到该地址执行.
- 多了一个 Program header,起始偏移地址为 52,紧随着 elf header.
- section 的数量增加到了 30 个,这是因为程序在链接过程中不仅仅包含用户编写的源代码,还会链接 glibc 库,增加的那些 section 从 glibc 而来,同时增加了 9 个 Program header,表示该程序有 9 个 segment.
2.2.3 动态库文件#
2.2.3.1 位置无关码#
当静态链接时,链接器为每条指令和数据分配独立的地址空间,当指令要访问数据时,访问的是数据的绝对地址。因此每个进程使用的库独立。
当动态链接时,多个进程共享一块内存的.text, 即共享库。因此使用相对地址,共享库相对于某个进程A,进程B,进程C有一个偏移量。
2.2.3.2 读头部#
使用 readelf -h 命令查看动态库的 elf 头,差异如下:
- 文件类型不一样,动态库的类型为 DNY(Shared object file)。
- 从动态库中段的组成来看,它和可执行文件几乎是差不多的,同时包含了 .init,.fini,.init_array,.fini_array,.text 等段内容,同时也有 segment table,这两者最大的差别在于:动态库的重定位过程放到加载时完成,因此其每个段,每个 segment 对应的虚拟地址都是不确定的,逻辑上从 0 开始。
- 动态库中的代码都是位置无关代码,这是由动态库共享的特性决定的
- 静态链接中,符号表、重定位表、字符串表这些都是作为链接阶段的辅助,所以在加载过程中属于无用的信息,但是动态库中这些段需要辅助动态库进行运行时的符号解析以及重定位,在加载时同样会被加载到内存中。
3 objcopy#
objcopy刚好和readelf相反,readelf是提取头部,而objdump是裁去掉头部,只剩二进制文件中的代码段,数据段,bss等。
1 | arm-linux-gnueabihf-objcopy -O binary -S -g led.elf led.bin |
“binary”表示以二进制格式输出,选项“-S”表示不要复制源文件中的重定位信息和符号信息,“-g”表示不复制源文件中的调试信息
4 objdump#
反汇编.
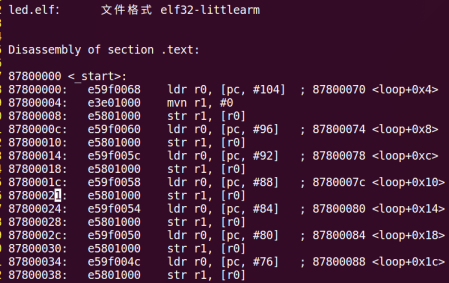
1 | arm-linux-gnueabihf-objdump -D led.elf > led.dis |
5 addr2line#
当程序出现crash掉后,会打印出异常信息地址,addr2line可以通过地址来用来对可执行程序找出源代码的文件函数行号具体位置。前提条件是gcc编译用-g选项。
6 size#
size命令用于查看elf文件的进程地址空间各段的大小.
7 nm#
nm命令用来查看可执行程序的符号表。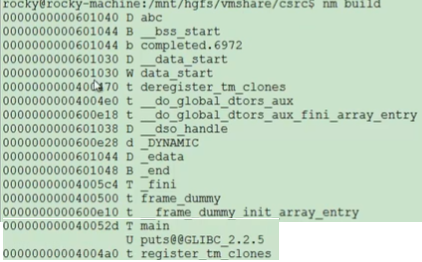
第1列表示符号地址,第2列表示符号类型,T表示全局的函数,D表示全局变量,d表示静态变量, t表示静态函数。如上图main函数就是T类型。第3列表示符号。
8 strip#
strip命令用来剔除符号表。可以看到对于可执行文件,一般都是包含符号表的,那么为了节省可执行程序空间,用strip可以剔除符号表。
剔除符号表后不影响可执行程序的功能。
下图可以看到strip后可执行文件变小了,用file命令查看状态变成了stripped, 用nm命令可以看到符号表已经消失。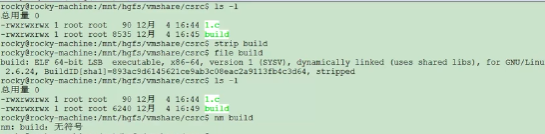
9 strings#
查看可执行程序中的用双引号表示的字符串,比如printf("hello world\n"); 这里hello world就属于strings。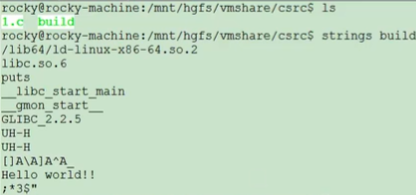
12 gcc#
源代码编译
1 | arm-linux-gnueabihf-gcc -g -c led.s -o led.o |
12.1 常用选项#
| 参数 | 含义 |
|---|---|
| -o | 指定文件输出路径 |
| -E | 对源文件进行预处理操作,输出.i文件 |
| -S | 对源文件进行预处理、编译操作,输出.s文件 |
| -c | 对源文件进行预处理、编译、汇编操作,输出.o文件 |
| -I | 包含头文件路径 例:gcc -I src/include/ |
| -L | 添加链接库路径 例: gcc -L src/lib/ |
| -l | 链接库文件 例: gcc -llibA.so |
| -fPIC | 生成位置无关代码(position-independent code) |
| -Wall | 对代码所有可能有问题的地方发出警告 |
| -g | 在目标文件中嵌入调试信息,便于gdb调试 |
| -v | 打印出gcc编译一个文件的时候所有的步骤 |
| -D | 使用编译时的宏 例子:gcc -Wall -DMY_MACRO main.c -o main |
| -std | 指定支持的c/c++标准 例:gcc -std=c++11 main.cpp |
| -static /-shared | 静态编译文件(把动态库的函数和其它依赖都编译进最终文件) or 动态编译文件 |
| -O(n) | 优化等级 |
12.2 编译过程#
分4个阶段:预处理、编译、汇编、链接。
12.2.1 预处理#
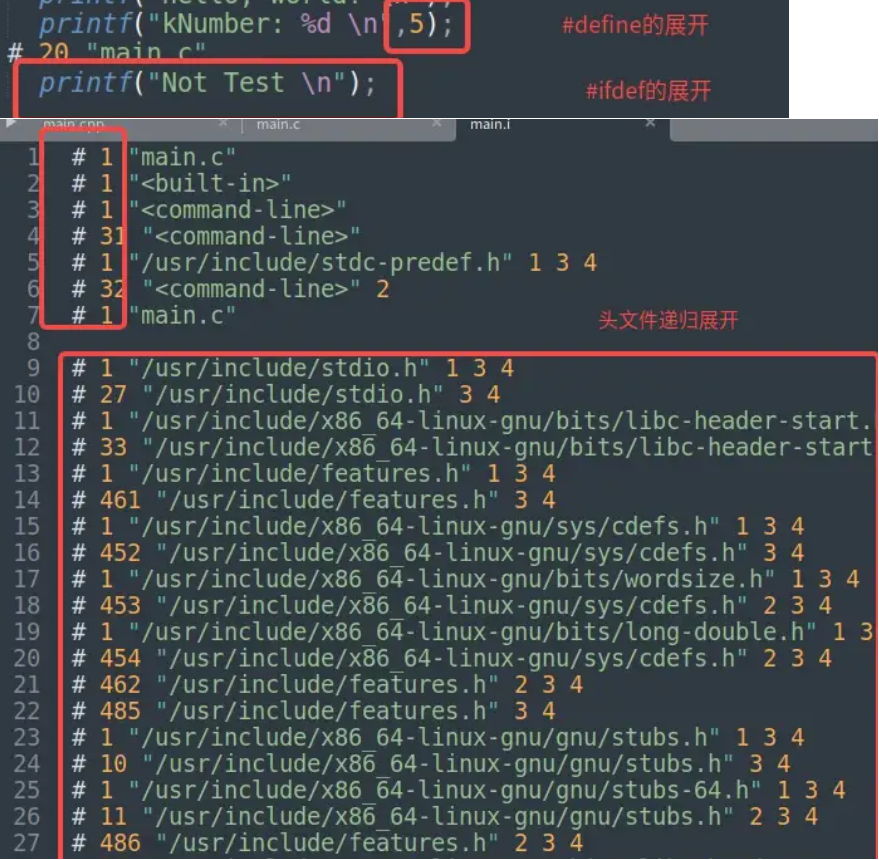
预编译阶段主要处理源文件中的以“#”开始的预编译指令。比如“#include”、“#define”。预处理会对头文件递归展开,宏定义进行替换。
gcc -E main.c -o main.i
12.2.2 编译#
生成相应的汇编代码.
1 | gcc -S main.c -o main.s |
12.2.2.1 强弱符号和强弱引用#
- 强符号屏蔽弱符号
1 | void test_func(void);//test.h |
1 | gcc -c test.c |
输出结果:
1 | custom strong func override! |
比如我们调用其他人的库,但是不得不自己去实现库里面的函数xxx, 那么就可以在对应头文件申明xxx是一个弱函数。
- 强弱引用
1 | void test_func(void);//test.h |
输出结果:
1 | running custom weak ref function! |
当把弱引用声明去掉,输出结果:
1 | running custom weak ref function! |
12.2.3 汇编#
将汇编代码转换成二进制机器代码,也就是目标文件。汇编使用as指令完成的。
1 | gcc -c main.s -o main.o |
12.2.4 链接#
汇编将代码编译成了二进制文件,但还需要和系统其他组件(比如标准库、动态链接库等)结合起来才能正常运行,比如调用print函数打印。链接就是打包各种目标文件。
1 | gcc hello.o sub.o display.o -o hello |
12.2.4.1 链接器#
链接器,-Ttext表示链接地址,也就是运行地址。一般会用lds链接脚本来进行。
1 | arm-linux-gnueabihf-ld -Ttext 0X87800000 led.o -o led.elf |
12.2.4.2 动态静态库#
1 | gcc -fpic -shared -o libhello.so hello.o |
12.2.4.3 链接选项#
1 | -L 指定链接库的目录 |
12.2.4.n 链接脚本lds#
1 SECTIONS{
2 . = 0X87800000;
3 .text :
4 {
5 start.o
6 main.o
7 *(.text)
8 }
9 .rodata ALIGN(4) : {*(.rodata*)}
10 .data ALIGN(4) : { *(.data) }
11 __bss_start = .;
12 .bss ALIGN(4) : { *(.bss) *(COMMON) }
13 __bss_end = .;
14 }
第 2 行设置定位计数器为0X87800000,因为我们的链接地址就是0X87800000。
第5行设置链接到开始位置的文件为start.o,因为 start.o 里面包含着第一个要执行的指令,所以一定要链接到最开始的地方。
第 6 行是 main.o这个文件,其实可以不用写出来,因为 main.o 的位置就无所谓了,可以由编译器自行决定链接位置。
第9行第10行定义了只读数据段和数据段。ALIGN(4)表示地址按照4对齐。
在第 11、13 行有“__bss_start”和“__bss_end”这两个东西?这个是什么呢?“__bss_start”和“__bss_end”是符号,第 11、13 这两行其实就是对这两个符号进行赋值,其值为定位符“.”,这两个符号用来保存.bss 段的起始地址和结束地址。前面说了.bss 段是定义了但是没有被初始化的变量,我们需要手动对.bss 段的变量清的,因此我们需要知道.bss 段的起始和结束地址,这样我们直接对这段内存赋 0 即可完成清零。通过第 11、13 行代码,.bss 段的起始地址和结束地址就保存在了“__bss_start”和“__bss_end”中,我们就可以直接在汇编或者 C 文件里面使用这两个符号。
代码重定位和清bss详细原理介绍可以参考我之前的介绍:
https://fuzidage.github.io/2024/04/15/s3c2440%E8%A3%B8%E6%9C%BA%E7%BC%96%E7%A8%8B-%E4%BB%A3%E7%A0%81%E9%87%8D%E5%AE%9A%E4%BD%8D%E5%92%8C%E6%B8%85bss/
12.2.4.n.1 链接脚本语法#
12.2.4.n.1.1 MEMORY/SECTIONS#
1 | MEMORY |
属性 attr 部分是可选的,它主要有以下几个选项:
‘R’:只读段
‘W’:读写段
‘X’:可执行段
‘A’:需要分配内存的段
‘I’,’L’:初始化段
‘!’:和上述的属性合并使用,表示反转给出的属性
1 | MEMORY |
上述示例中,定义了两个内存区域,rom 区域从 0 开始,占据 256K 字节,而 ram 区域从 0x40000000 开始,占用 4M 空间.
而输出段 .text 指定放在 rom 中, .data 放在 ram 区域, .bss 没有指定,但是由于 .bss 段的属性是 ‘w’ 类型的,所以匹配的区域是 ram,被放在 .data 随后的地址处.
而地址定位符的赋值语句 ". = 0x80000000;" 会被忽略,编译完成之后可以通过 readelf -S 命令查看输出文件,可以看到各个段对应的虚拟地址.
在 linux 系统中,通常不会使用这种指定内存区域的定义方式,而是使用 SECTIONS 中的地址定位符,因为 linux 中对于系统内存的规定是比较严格的,通常不支持自定义的内存区域,而在裸机或者实时操作系统中这种方式使用得比较多.